Exploring Intel’s Omni-Path Network Fabric
by Ryan Smith on August 26, 2015 12:00 PM EST- Posted in
- HPC
- Networking
- Intel
- Xeon Phi
- Omni-Path

For several months now we have been talking about Intel’s Omni-Path network fabric, the company’s next-generation 100Gbps netwoking fabric technology. Typically Omni-Path has come up alongside discussions of Intel’s forthcoming 2nd generation of Xeon Phi products, codenamed Knights Landing. With Intel designing the two products alongside each other, and with Knights Landing due later this year, the company is now opening up a bit more about Omni-Path and how it works, including a paper on the technology for the IEEE Hot Interconnects conference this week and a press briefing on the technology at last week’s Intel Developer Forum 2015.
Intel is of course no stranger to network fabrics, having produced InfiniBand gear for a number of years under their True Scale brand. In 2012 the company went on a buying spree, picking up both QLogic’s InfiniBand technology and Cray’s interconnect technology as well. The long goal for Intel has been to develop a successor to InfiniBand and True Scale, one that would scale faster, better, and cheaper. The end result of these development efforts has been the creation of Omni-Path and the surrounding ecosystem.

The current Q-Logic True Scale Controllers
For Intel developing Omni-Path solves several goals for the company, many of them unsurprisingly tied closely to Xeon Phi. On the whole, fabric costs as a percentage of total HPC system costs has been going up, which for Intel is a problem on multiple levels. It decreases the amount of the bill of materials spent on Xeon Phi and other Intel hardware, it drives up overall system costs, and it presents a barrier to entry for customers. This has led to Intel to focus on bringing the cost down on fabrics, which in turn has led to the development of Omni-Path.
The biggest focus for Intel as far as costs control go is to work on integration, as over time integration brings down the number of components required and therefore brings down costs as well while increasing reliability. For this reason we will see versions of Knights Landing co-processors launching with on-package Omni-Path capabilities, although not in a full integrated fashion. In this case the company will be installing Omni-Path controllers on to Knights Landing chip packages in an MCM manner, meaning that the Knights Landing silicon itself won’t feature Omni-Path but the chip will, both sharing the PCIe interface. This ultimately sets the stage for future generations of Omni-Path and Xeon Phi by getting vendors and customers used to having it on-chip, with the successive (second) generation finally going fully integrated. The applicability extends to data leaving the Xeon Phi through the fabric without requiring further intra-node data organization.
Meanwhile as not every host will be a Xeon Phi, Intel is also developing PCIe Omni-Path cards as well. The cards will depending on the specific model support one or two Omni-Path ports via either PCIe 3.0 x16 or x8, though you’ll need the x16 card for full 100Gb/sec bandwidth. The TDP on these cards is said to be 8W, with a max power draw of 12W.

OPA Host Controller Engineering Sample
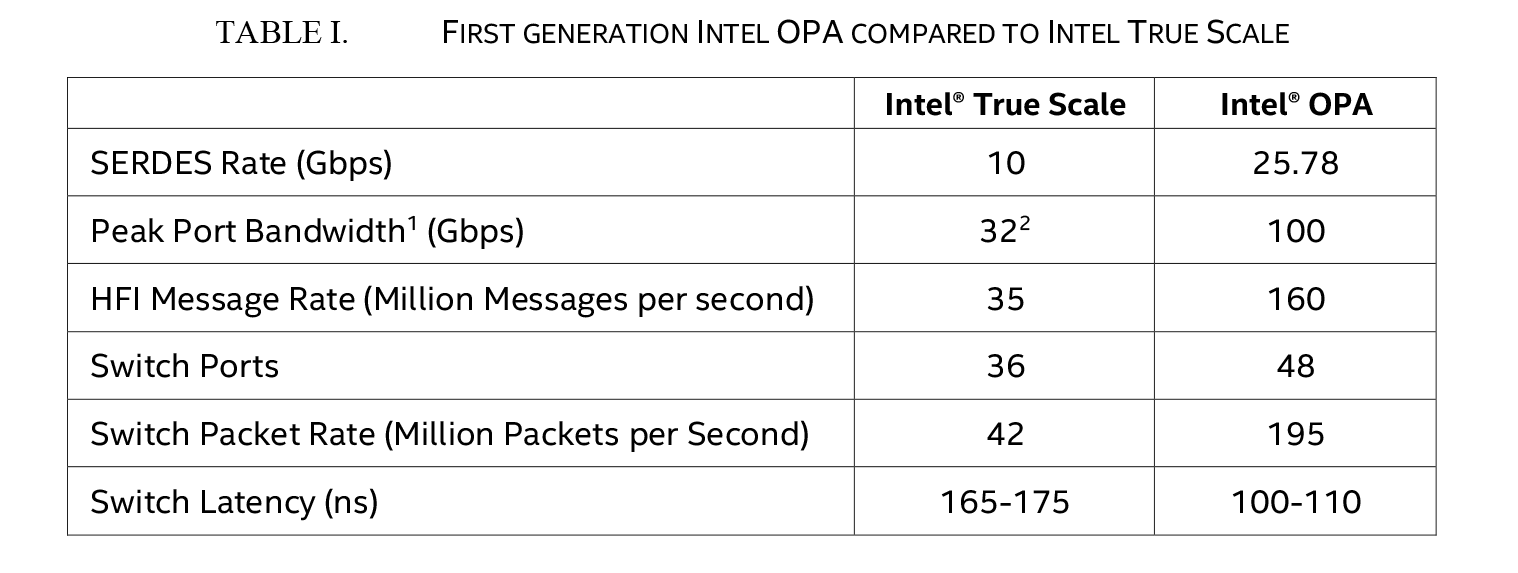
Along with the host adapters, Intel will also be designing other hardware elements of Omni-Path, such as switches, which will scale up to 48 ports per switch. The fact that Intel will be offering a 48 port switch is something that they consider to be a feather in their cap for Omni-Path, as larger switches allow for flatter network topology. With similar InfiniBand switches only scaling up to 36 ports per switch, a 48 port switch represents a 33% increase in the number of ports that can be switched. For a theoretical “sweet spot” one-thousand node Omni-Path design then, this would allow every node to be no more than 3 hops from any other node, whereas a topology with 36 nodes would stretch that out to 5 hops. The benefit of fewer hops, besides being fewer switches, is that it reduces the maximum latency for the fabric since any given packet will traverse fewer switches to get to its destination.
Omni-Path Fabric Architecture
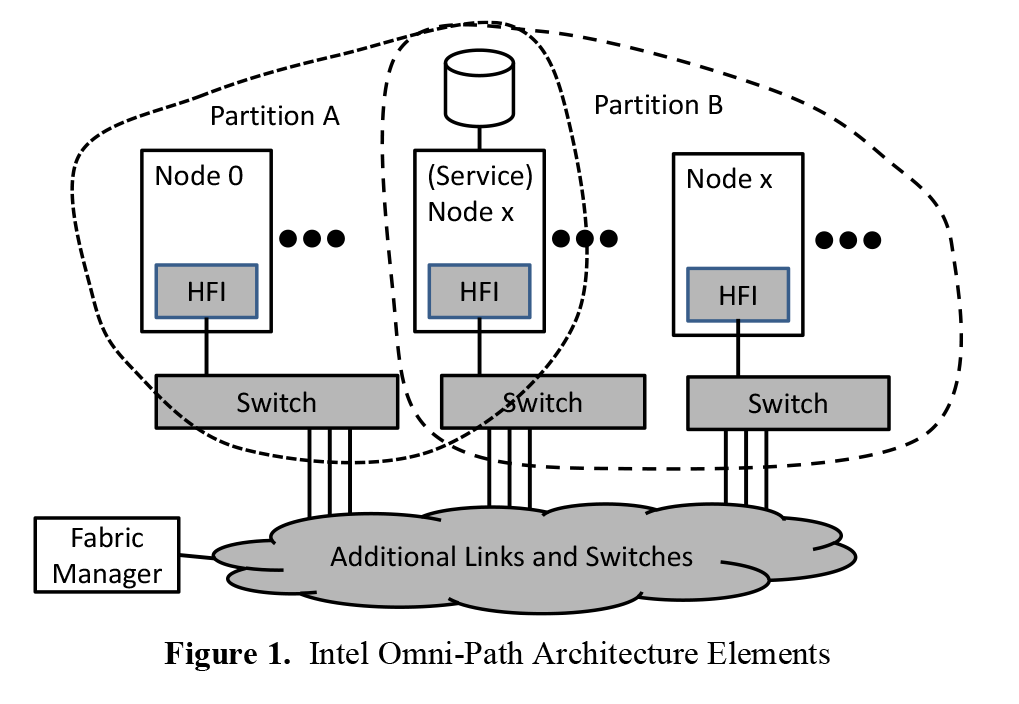
Diving into the fabric architecture itself, for Omni-Path Intel has attempted to prudently develop the architecture in such a way that it will outperform similar technologies (e.g. InfiniBand EDR), but also to do so while controlling costs. A big part of this has been designing the fabric to withstand higher bit error rates, as the greater error tolerances drive up the cost of the fabric, both with regards to equipment cost and the use of more expensive optical cable runs versus cheaper copper cable runs. To that end Intel is shooting for a bit error rate of 1E-12, or roughly a single bit error every 10 seconds when operating at 100Gb/sec.
Surprisingly, to manage these errors Omni-Path doesn’t use any form of error correction such as Forward Error Correction, but instead relies on a simpler CRC/retransmit mechanism. This is based on citing the fact that forward error correction causes a fair bit of latency due to the need to at two different packet levels, and then retransmit any failed packets from end-to-end. Omni-Path by comparison allows re-transmission at the hop-to-hop level, minimising latency and supporting a higher bit-error rate as a result. This means that Omni-Path does need to stop and request a retransmission end-to-end, but for a standard low-level packet error it can request the retransmission from the previous node as soon as it’s discovered, before a packet even moves through the switch to its target node.
Speaking of packets and links, for Omni-Path Intel has devised an interesting method of operating the fabric. Breaking a bit from the traditional 7 layer OSI model, the Omni-Path model essentially has two layers of packets, manifesting itself as an in-between layer of the model. The closest thing to traditional packets offered by Omni-Path is the Fabric Packet (FP), a node-to-node packet type that is generated by higher levels of the stack. However FPs aren’t transmitted as-is, and instead are broken down into what Intel calls the Link Transfer Packet (LTP). The LTP is a smaller link-local packet, and with Intel describing this as a kind of Layer 1.5 packet. It is at this level that retransmission of packets occurs in the event of bit-errors.
Representation from http://infosys.beckhoff.com/
It’s at the LTP layer where most of the real work takes place. The LTPs are 1056 bits in length and contain a combination of data (1024 bits), FLIT type bits (16 bits, 1 for each FLIT), CRC information (14 bits), and what Intel calls virtual lane credit bits (2 bits). On the data side, the 1024 data bits are in turn split up into 16x 64-bit Flow Control Digits (FLITs), which are ultimately the smallest unit of data. As LTPs can contain FLITs from multiple FPs, the FLITs are how data from multiple FPs within a single LTP is kept organized.
Overall the fact that the LTP is 1056 bits in size and contains 1024 bits of data gives the LTP an efficiency equivalent to 64/66b encoding, similar to other fabric standards. Intel uses a bit-scrambler here in order to provide the necessary protection against running disparity without having to use further encoding and padding on top of the LTP. Coupled with this, Intel ever so slightly overclocks the Omni-Path link layer, such that it runs at 25.78125Gbps, which after the overhead of the LTP gives Omni-Path a proper 100Gb/sec of bandwidth at the link layer level.

Getting back to error resilience for a moment then, we can see how error detection and transmission works under this model. The LTPs having their own 14-bit CRC means that a link can request a retransmission should an LTP become corrupt, catching it after just 1056 bits and before an LTP moves on to the next link in a route. Meanwhile, in the unlikely event that an error still makes it through, then the FP error check at the destination node will find the error and trigger a retransmission of the whole FP.
Finally, let’s talk a bit about packet prioritization, via what Intel calls Traffic Flow Optimization. Because LTPs can be composed of data from multiple FPs via the use of FLITs, Omni-Path has a relatively simple method to handle packet prioritization. Higher priority FPs are simply given space on the current LTP, bumping the lower priority FP already in progress, and the lower priority FP can complete whenever it is not being blocked by higher priority traffic. Intel cites this as giving Omni-Path better latency, as higher priority packets have a minimal wait time (a 16-bit FLIT) before being able to assume control of the link. Overall Omni-Path supports 32 priority levels, though Intel expects first-gen setups to use something between 4 and 8.
Closing Thoughts

While the purpose of Intel’s Omni-Path disclosure is in part to help advertise the technology and entice potential customers looking for a 100Gb/sec fabric, Intel does already have some customers lined up for the fabric. The company is telling the press and public that there are already over 100 OEM designs in the pipeline, with bids/contracts on over 100K nodes in total.
Finally, given Omni-Path’s close development alongside Xeon Phi, unsurprisingly the two will be close together in deployment. As disclosed in Intel’s presentation, the company is already sampling OEMs. The first customer deployments are expected in Q4 of this year, with broader availability and rollout to follow in 2016.








16 Comments
View All Comments
alphasquadron - Wednesday, August 26, 2015 - link
Can someone tell me how this will affect a normal consumer. Does this allow processors to be faster or something. Or is this network related.mmrezaie - Wednesday, August 26, 2015 - link
It's datacenter or HPC related mostly, and very important one too. It can massively increase IO related applications performance usually in big data area.zoxo - Wednesday, August 26, 2015 - link
If you are a normal customer, this does not affect you in any way.JKflipflop98 - Wednesday, August 26, 2015 - link
A very long time from now, the technology used here will lead to products you use at home. As of right now, this is super-spendy "big iron" type stuff.vision33r - Wednesday, August 26, 2015 - link
I like to see what game or app you use at home that can push that much data through the interface.repoman27 - Wednesday, August 26, 2015 - link
GPUs can. Think CrossFire or SLI but the GPUs are in separate devices connected by Omni-Path. If you have several PCs you could tap all of their resources from whichever one you happen to be sitting at across the network.frenchy_2001 - Wednesday, August 26, 2015 - link
It won't.This is a technology to link multiple nodes in a "Big Data" Server, a super comuter.
This will *NOT* come to consumers anytime soon and quite honestly, consumers have no real use for it at the moment.
repoman27 - Wednesday, August 26, 2015 - link
Well, actually, it already has in a way. Although it's not designed as a network fabric, mostly because Intel isn't interested in producing dedicated switches for it and potentially cannibalizing a more lucrative market, Thunderbolt isn't too far off from a consumer version of Omni-Path. Consider the upcoming Alpine Ridge Thunderbolt 3 controllers vs. Omni-Path:80% of SerDes rate (20.625 Gbit/s vs 25.78125 Gbit/s)
1/2 the channels per port (2C vs. 4C)
40% of peak port bandwidth
25% of PCIe back-end bandwidth (PCIe 3.0 x2 or x4 vs. PCIe 3.0 x8 or x16)
No dedicated switches
Latency ~3x higher (although it’s hard to say at this point for TB3)
35% of TDP (2.8 W vs. 8 W) or 17.5% if we believe Intel’s claims of “50% reduced power” with TB3
60x smaller receptacle (USB Type-C at 8.34 x 2.56 x 6.2 mm vs. QSFP28 at 19 x 8.8 x 48 mm)
Intel’s recommended customer price is $9.95 vs. ???
Cables cost 2-4x less ($14.50 - $60.00 / m for 0.5 to 60 m active copper and optical cable assemblies vs. $30.00 - $256.00 / m for 0.5 to 50 m passive copper and active optical cable assemblies)
You may be right in that consumers haven't found a real use for Thunderbolt either, but creatives, professionals and academics certainly have.
extide - Friday, August 28, 2015 - link
x2 ^^^ The real science is in the 20-25Gbit SERDES rates these things are using. No doubt that there is a lot of crossover in the development of OmniPath and TB3, in that regard.donwilde1 - Saturday, August 29, 2015 - link
Actually, it affects you concretely. Your Siri will be faster. Your weather predictions will come faster. Virtually any app that accesses complex cloud data will -- as these are adopted -- return information to you faster. It is unlikely that these will be used for simple websites, but anything that requires computation, such as voice recognition or facial pattern recognition or data analytics will operate faster.