NVIDIA @ ICML 2015: CUDA 7.5, cuDNN 3, & DIGITS 2 Announced
by Ryan Smith on July 7, 2015 4:00 AM EST
Taking place this week in Lille, France is the 2015 International Conference on Machine Learning, or ICML. Now in its 32nd year, the annual event is one of the major international conferences focusing on machine learning. Coinciding with this conference are a number of machine learning announcements, and with NVIDIA now heavily investing in machine learning as part of their 2015 Maxwell and Tegra X1 initiatives with a specific focus on deep neural networks, NVIDIA is at the show this year to release some announcements of their own.
All-told, NVIDIA is announcing new releases for three of their major software libraries/environments, CUDA, cuDNN, and DIGITS. While NVIDIA is primarily in the business of selling hardware, the company has for some time now focused on the larger GPU compute ecosystem as a whole as a key to their success. Putting together useful and important libraries for developers helps to make GPU development easier and to attract developer interest from other platforms. Today’s announcements in turn are Maxwell and FP16-centric, with NVIDIA laying the groundwork for neural networks and other half-precision compute tasks which the company believes will be important going forward. Though the company only has a single product so far that has a higher performance FP16 mode – Tegra X1 – it has more than subtly been hinted at that the next-generation Pascal GPUs will incorporate similar functionality, making for all the more reason for NVIDIA to get the software out in advance.
CUDA 7.5
Starting things off we have CUDA 7.5, which is now available as a release candidate. The latest update for NVIDIA’s GPU compute platform is a smaller release as one would expect for a half-version update, and is primarily focused on laying the API groundwork for FP16. To that end CUDA 7.5 introduces proper support for FP16 data, and while non-Tegra GPUs still don’t receive a compute performance benefit from using FP16 data, they do benefit from reduced memory pressure. So for the moment NVIDIA is enabling this feature for developers to take advantage of any performance benefits from the reduced memory bandwidth needs and/or allowing for larger datasets in the same amount of GPU memory.
Meanwhile CUDA 7.5 is also introducing new instruction level profiling support. NVIDIA’s existing profiling tools (e.g. Visual Profiler) already go fairly deep, but now the company is looking to go one step further in helping developers identify specific code segments and instructions that may be holding back performance.
cuDNN 3
NVIDIA’s second software announcement of the day is the latest version of the CUDA Deep Neural Network library (cuDNN), NVIDIA’s collection of GPU accelerated neural networking functions, which is now up to version 3. Going hand-in-hand with CUDA 7.5, a big focus on cuDNN 3 is support for FP16 data formats for existing NVIDIA GPUs in order to allow for more efficient memory and memory bandwidth utilization, and ultimately larger data sets.

Meanwhile separate from NVIDIA’s FP16 optimizations, cuDNN 3 also includes some optimized routines for Maxwell GPUs to speed up overall performance. NVIDA is telling us that FFT convolutions and 2D convolutions have both been added as optimized functions here, and that they are touting an up to 2x increase in neural network training performance on Maxwell GPUs.
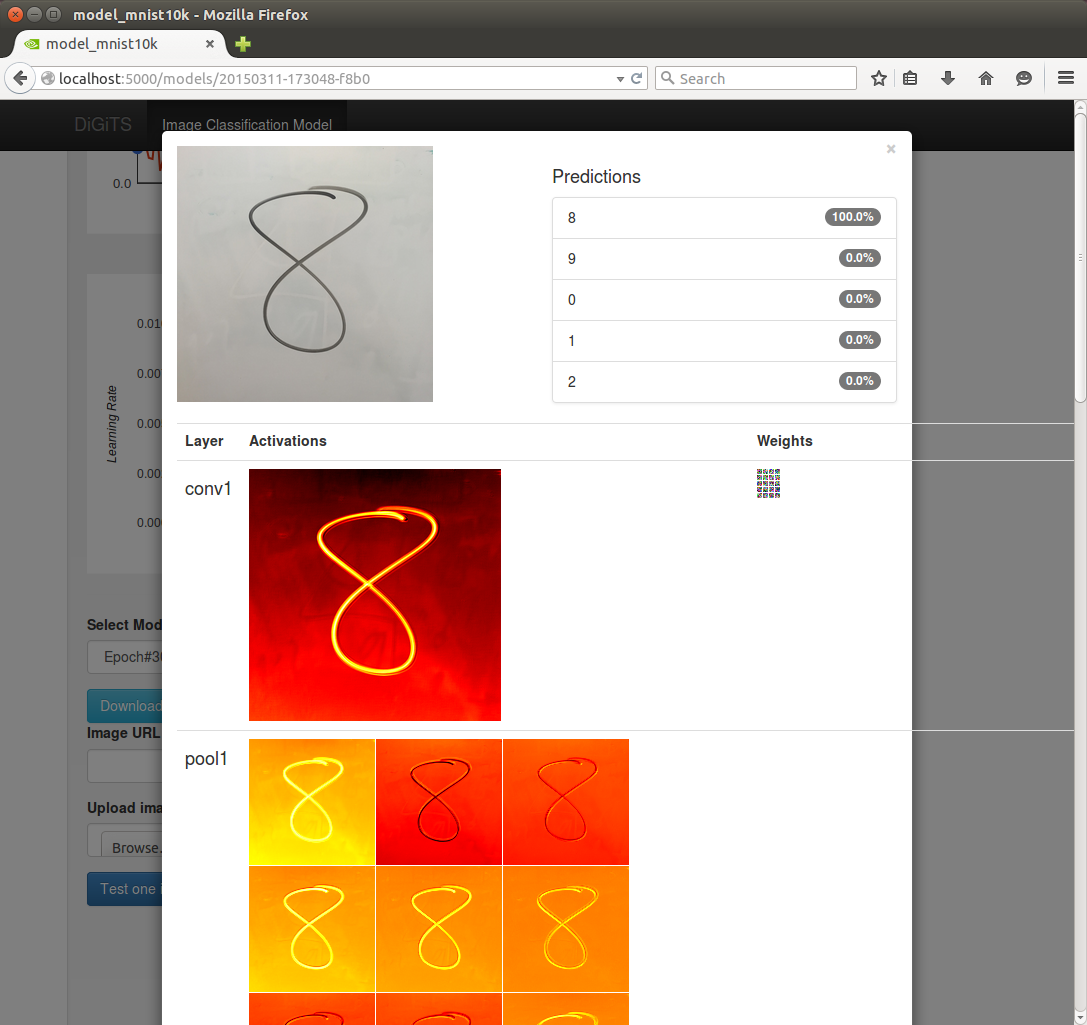
DIGITS 2
Finally, built on top of CUDA and cuDNN is DIGITS, NVIDIA’s middleware for deep learning GPU training. First introduced just back in March at the 2015 GPU Technology Conference, NVIDIA is rapidly iterating on the software with version 2 of the package. DIGITS, in a nutshell, is NVIDIA’s higher-level neural network software for general scientists and researchers (as opposed to programmers), offering a more complete neural network training system for those users who may not be accomplished computer programmers or neural network researchers.
NVIDIA® DIGITS™ Deep Learning GPU Training System
DIGITS 2 in turn introduces support for training neural networks over multiple GPUs, going hand-in-hand with NVIDIA’s previously announced DIGITS DevBox (which is built from 4 GTX Titan Xs). All things considered the performance gains from using multiple GPUs are not all that spectacular – NVIDIA is touting just a 2x performance increase in going from 1 to 4 GPUs – though for performance-bound training this none the less helps. Looking at NVIDIA’s own data, it looks like scaling from 1 to 2 GPUs is rather good, but scaling from 2 to 4 GPUs is where the performance gains from scaling slow down, presumably due to a combination of bus traffic and synchronization issues over a larger number of GPUs. Though on that note, it does make me curious whether the Pascal GPUs and their NVLink buses will improving multi-GPU scaling at all in this scenario.
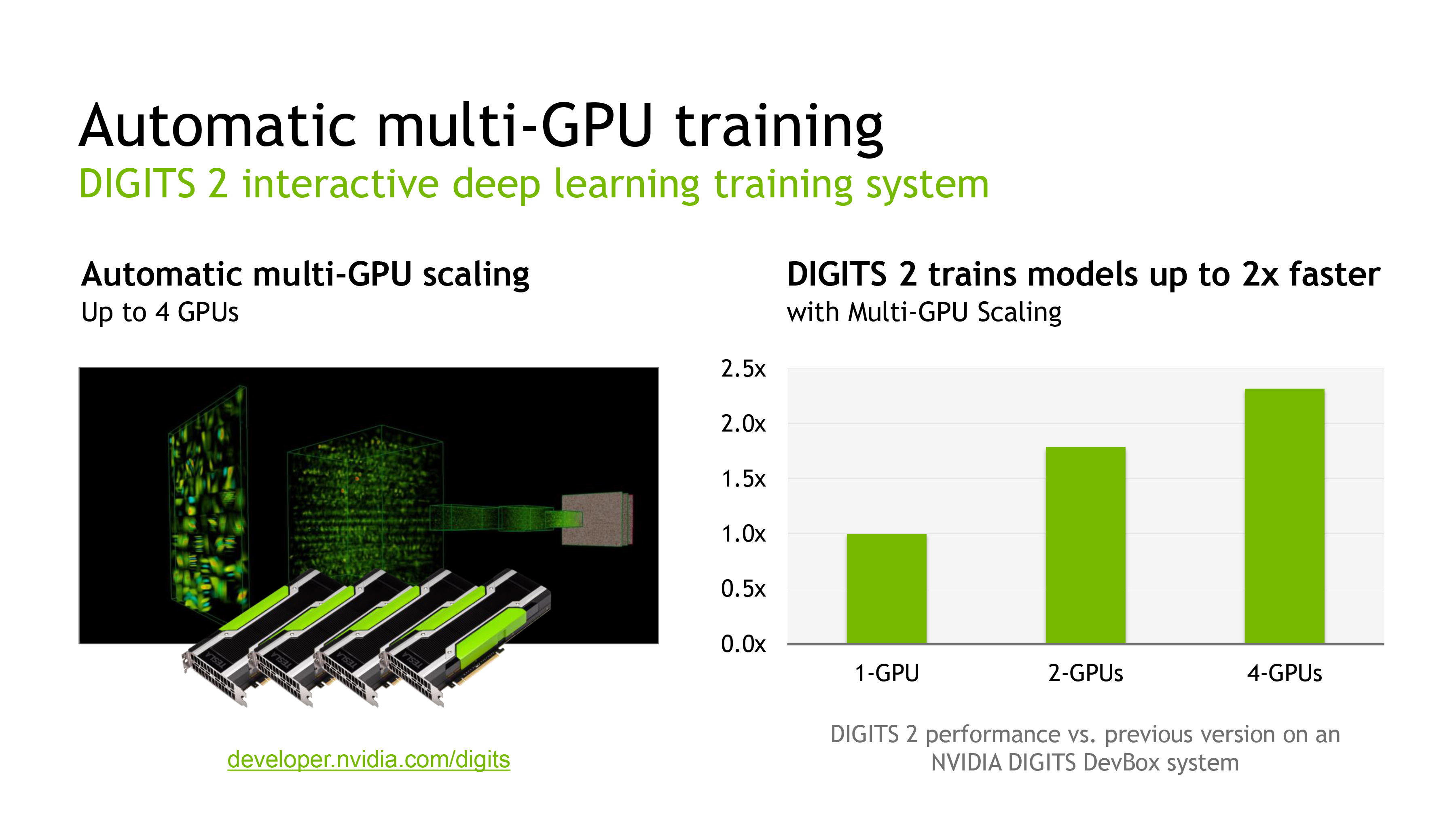
In any case, the preview release of DIGITS 2 is now available from NVIDIA, though the company has not stated when a final version will be made available.
Source: NVIDIA








26 Comments
View All Comments
Terry Suave - Tuesday, July 7, 2015 - link
"Though the company only has a single product so far that has a higher performance FP16 mode – Tegra X1 – it has more than subtly been hinted at that the next-generation Pascal GPUs will incorporate similar functionality"Now, I am no expert on compute (I barely know the difference between precision levels), but if Nvidia is concentrating on half-precision workload performance, does that mean 32 and 64 bit performance will be worse? I mean, Maxwell is already worse by some margin than Keplar was at Double precision, so is it just something that isn't used very often? Or, is this not the case at all and I'm drawing all the wrong conclusions?
MrSpadge - Tuesday, July 7, 2015 - link
FP64 is being reduced for these reasons:- it's not needed for almost any client workloads
- it's badly needed in many professional workloads
It's not too difficult to build 2 FP32 units which can also work together as 1 FP64 unit. You need more transistors than for 2 regular FP32 units, though, which hurts consumer GPUs. For FP16 this tradeoff may well be worth it, because the regular shaders are already "big", i.e. support FP32, so they won't become much larger by allowing them to work as 2 FP16 units. If it's used, this ability saves bandwith, memory space, power (which can be used to reach higher clocks) and allows significantly higher performance with new the hardware. For some client workloads FP16 will be enough, so this sounds pretty good.
p1esk - Tuesday, July 7, 2015 - link
"It's not too difficult to build 2 FP32 units which can also work together as 1 FP64 unit"It's not clear to me how to combine 2 32 bit FP units into 1 64 bit unit. Care to explain? Or provide some reference?
MrSpadge - Wednesday, July 8, 2015 - link
In CPUs this has been done for ages. They can't utilize many ALUs / FP units, but must be very flexible. Hence the tradeoff "some more transistors per unit" is well worth it for them. As far as I know AMD is also doing it on their GPUs with considerable FP64 capability.p1esk - Wednesday, July 8, 2015 - link
No, Intel CPUs for example, as far as I understood, did FP with 80 bit precision FP units, then rounded them off to produce either 32 or 64 bit results.Again, combining two FP32 units into one FP64 units seems to be impossible to be. Just look at the number formats - FP64 has more than twice mantissa bits than FP32. It might be possible to perform FP64 operation using a single FP32 unit, by doing multiple passes, but this too is not clear to me.
MrSpadge - Wednesday, July 8, 2015 - link
No, 80 bit is the internal precision for FP64. For FP32 this would be totally overkill. It's very normal for Intel CPUs (and AMD, btw) to have twice the maximum FP32 throughput than FP64:http://www.nas.nasa.gov/hecc/support/kb/Ivy-Bridge...
https://software.intel.com/de-de/forums/topic/3942...
"It might be possible to perform FP64 operation using a single FP32 unit, by doing multiple passes, but this too is not clear to me. "
That's what they're doing if the FPU should stay very small (AMDs cat-cores, Intel Silvermont).
How it's done EXACTLY is not clear to me either, as I'm not a circuit engineer. But I know it's pretty standard stuff, so look it up if you're really interested.
p1esk - Wednesday, July 8, 2015 - link
Here's a diagram of the 8087 FP coprocessor: it's clear that both FP32 and FP64 use 80 bit precision:https://en.wikipedia.org/wiki/Intel_8087#/media/Fi...
I did try to look it up, but haven't found any good info. I don't need to know exactly how it's done, a diagram showing the design of FP units in a modern CPU or GPU would be sufficient.
MrSpadge - Thursday, July 9, 2015 - link
What I see there is simply all 8 stack registers using 80 bit and the busses being 16+64 bit wide. That does not automatically mean the execution unit(s?) would use the full 80 bit internally for FP32. That would be a waste of energy.. but power consumption was no big factor for those old CPUs.Anyway, after some searching I found this regarding AMDs VLIW architecture:
http://www.realworldtech.com/cayman/6/
"AMD’s VLIW pipelines are a multi-precision, staggered design that can bypass results between the pipelines." - these may be the keywords to look for.
p1esk - Thursday, July 9, 2015 - link
The x87 FP coprocessor did use 80 bit FP ALU even for FP32, and in fact when it was present, it was used for all ALU operations, including 32 bit integer ops. It's long obsolete though, probably due to the energy/area efficiency issues you mentioned.From your AMD link, and also from some info I found on Maxwell, it turns out all modern GPUs include both FP32 and FP64 units. Typically a lot fewer FP64 than FP32, that's where a typical 64 vs 32 performance ratio comes from when describing GPU architectures e.g. Maxwell 200 is 32:1, because for every SSM there are 128 FP32 units and only 4 FP64 units.
However, I still could not find any info about FP ALUs in modern CPUs. For example, Haswell can process 256 bit wide FP vectors. These can be a set of 32 bit FP values, or a set of 64 bit FP values. But it's not clear if it uses the same FP64 units for all FP ops, or if there's a mix of FP64 and FP32 units, like in GPUs.
saratoga4 - Thursday, July 9, 2015 - link
Its the same multiplier used in all cases. Theres control lines that set the precision and number of parallel operations used. Putting in multiple 256 bit wide FPUs that could not be used in parallel wouldn't make sense, it'd be a huge waste of power/area.ARM is even more interesting with NEON. On parts with small dies, the NEON floating point multipliers are only 32 bits wide, so a 64 bit vector needs the multiplier for 2 cycles, whereas a 128 not vector needs it for 4. On the more advanced ARM devices, the multiplier unit is itself 128 bits wide, so the performance is the same.