Compute Express Link (CXL) 3.0 Announced: Doubled Speeds and Flexible Fabrics
by Ryan Smith on August 2, 2022 9:00 AM ESTWhile it’s technically still the new kid on the block, the Compute Express Link (CXL) standard for host-to-device connectivity has quickly taken hold in the server market. Designed to offer a rich I/O feature set built on top of the existing PCI-Express standards – most notably cache-coherency between devices – CXL is being prepared for use in everything from better connecting CPUs to accelerators in servers, to being able to attach DRAM and non-volatile storage over what’s physically still a PCIe interface. It’s an ambitious and yet widely-backed roadmap that in three short years has made CXL the de facto advanced device interconnect standard, leading to rivals standards Gen-Z, CCIX, and as of yesterday, OpenCAPI, all dropping out of the race.
And while the CXL Consortium is taking a quick victory lap this week after winning the interconnect wars, there is much more work to be done by the consortium and its members. On the product front the first x86 CPUs with CXL are just barely shipping – largely depending on what you want to call the limbo state that Intel’s Sapphire Ridge chips are in – and on the functionality front, device vendors are asking for more bandwidth and more features than were in the original 1.x releases of CXL. Winning the interconnect wars makes CXL the king of interconnects, but in the process, it means that CXL needs to be able to address some of the more complex use cases that rival standards were being designed for.
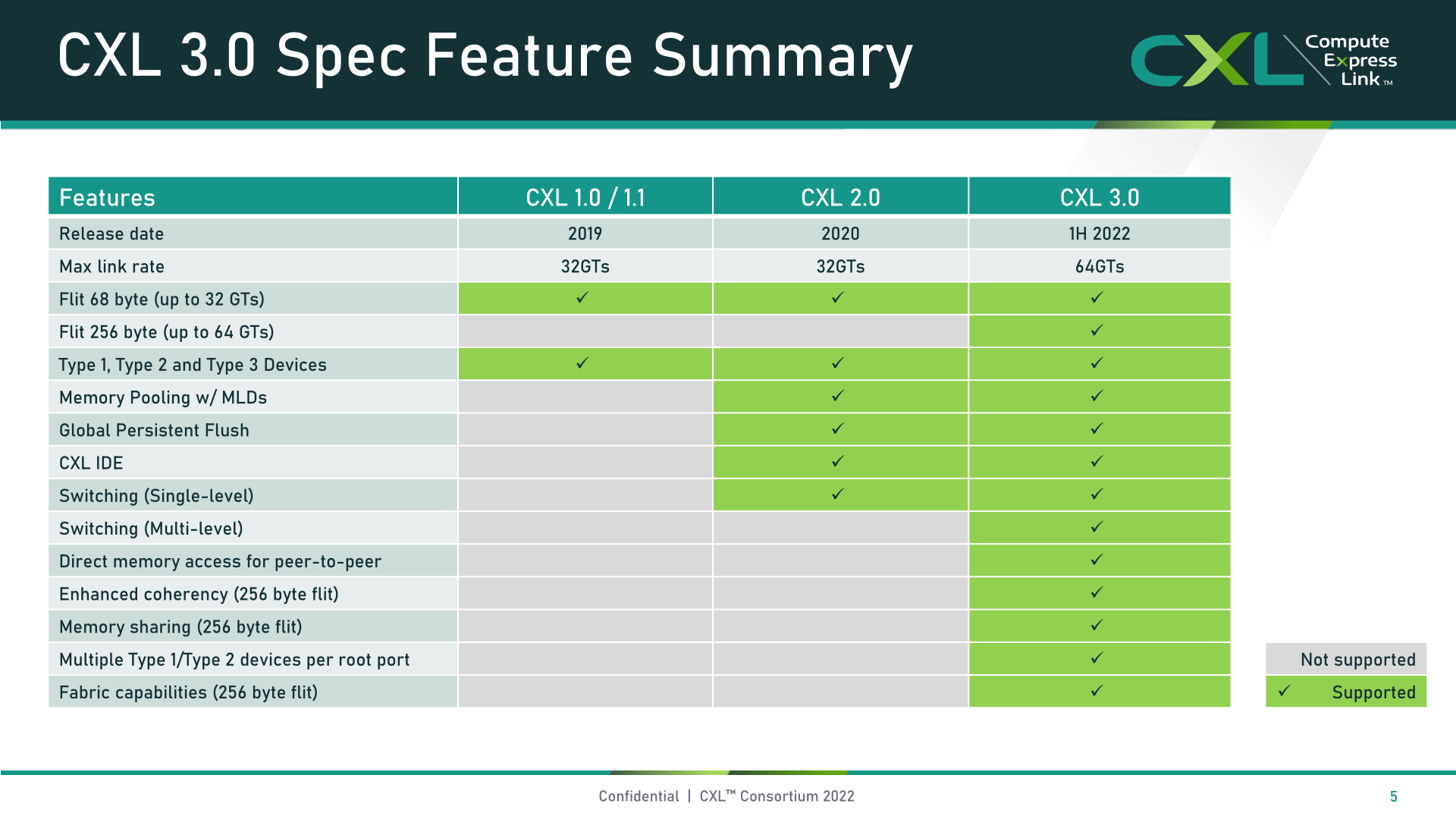
To that end, at Flash Memory Summit 2022 this week, the CXL Consortium is at the show to announce the next full version of the CXL standard, CXL 3.0. Following up on the 2.0 standard, which was released at the tail-end of 2020 and introduced features such as memory pooling and CXL switches, CXL 3.0 focuses on major improvements in a couple of critical areas for the interconnect. The first of which is the physical side, where is CXL doubling its per-lane throughput to 64 GT/second. Meanwhile, on the logical side of matters, CXL 3.0 is greatly expanding the logical capabilities of the standard, allowing for complex connection topologies and fabrics, as well as more flexible memory sharing and memory access modes within a group of CXL devices.
CXL 3.0: Built On Top of PCI-Express 6.0
Starting with the physical aspects of CXL, the new version of the standard delivers on the long-awaited update to incorporate PCIe 6.0. Both previous versions of CXL, that is to say 1.x and 2.0, were built on top of PCIe 5.0, so this is the first time since CXL’s introduction in 2019 that its physical layer has been updated.
Itself a major update to the inner workings of the PCI-Express standard, PCIe 6.0 yet again doubled the amount of bandwidth available over the bus to 64 GT/second, which for a x16 card works out to 128GB/sec. This was accomplished by transitioning PCIe from using binary (NRZ) signaling to quad-state (PAM4) signaling and incorporating a fixed packet (FLIT) interface, allowing it to double speeds without the drawbacks of operating at even higher frequencies. Since CXL in turn is built on top of PCIe, this meant that the standard needed to be updated to account for the operational changes to PCIe.

The end result for CXL 3.0 is that it inherits the full bandwidth improvements of PCIe 6.0 – along with all the fun stuff like forward error correction (FEC) – doubling CXL’s total bandwidth as compared to CXL 2.0.
Notably, according to the CXL Consortium they’ve been able to accomplish all of this without an increase in latency. This was one of the challenges the PCI-SIG faced in designing PCIe 6.0, as the necessary error correction would add latency to the process, resulting in the PCI-SIG using a low-latency form of FEC. Still, CXL 3.0 takes things one step further in attempting to reduce latency, resulting in 3.0 having the same latency as CXL 1.x/2.0.
As well as the base PCIe .60 update, the CXL Consortium has also tweaked their FLIT size. Whereas CXL 1.x/2.0 used a relatively small 68 byte packet, CXL 3.0 bumps this up to 256 bytes. The much larger FLIT size is one of the key communications changes with CXL 3.0, as it gives the standard many more bits in the header FLIT, which in turn are needed to enable the complex topologies and fabrics the 3.0 standard introduces. Though as an added feature, CXL 3.0 also offers a low-latency “variant” FLIT mode that breaks up the CRC into 128 byte “sub-FLIT granular transfers”, which is designed to mitigate store-and-forward overheads in the physical layer.
Notably, the 256 byte FLIT size keeps CXL 3.0 consistent with PCIe 6.0, which itself uses a 256 byte FLIT. And like its underlying physical layer, CXL supports using the large FLIT not only at the new 64 GT/sec transfer rate, but also 32, 16, and 8 GT/sec, essentially allowing the new protocol features to be used with slower transfer rates.
Finally, CXL 3.0 is fully backwards compatible with earlier versions of CXL. So devices and hosts can downgrade as needed to match the rest of the hardware chain, albeit losing newer features and speeds in the process.
CXL 3.0 Features: Enhanced Coherency, Memory Sharing, Multi-Level Topologies, and Fabrics
Besides further improving on overall I/O bandwidth, the aforementioned protocol changes for CXL have also been implemented in service of enabling new features within the standard. CXL 1.x was born as a (relatively) simple host-to-device standard, but now that CXL is the dominant device interconnect protocol for servers, it needs to expand its capabilities both to accommodate more advanced devices, and ultimately to accommodate greater use cases.
Kicking things off at the feature level, the biggest news here is that the standard has updated the cache coherency protocol for devices with memory (Type-2 and Type-3, in CXL parlance). Enhanced coherency, as CXL calls it, allows for devices to back invalidate data that’s being cached by a host. This replaces the bias-based coherency approach used in earlier versions of CXL, which to keep things brief, maintained coherency not so much by sharing control of a memory space, but rather by either putting the host or device in charge of controlling access. Back invalidation, in contrast, is much closer to a true shared/symmetric approach, allowing CXL devices to inform a host when the device has made a change.
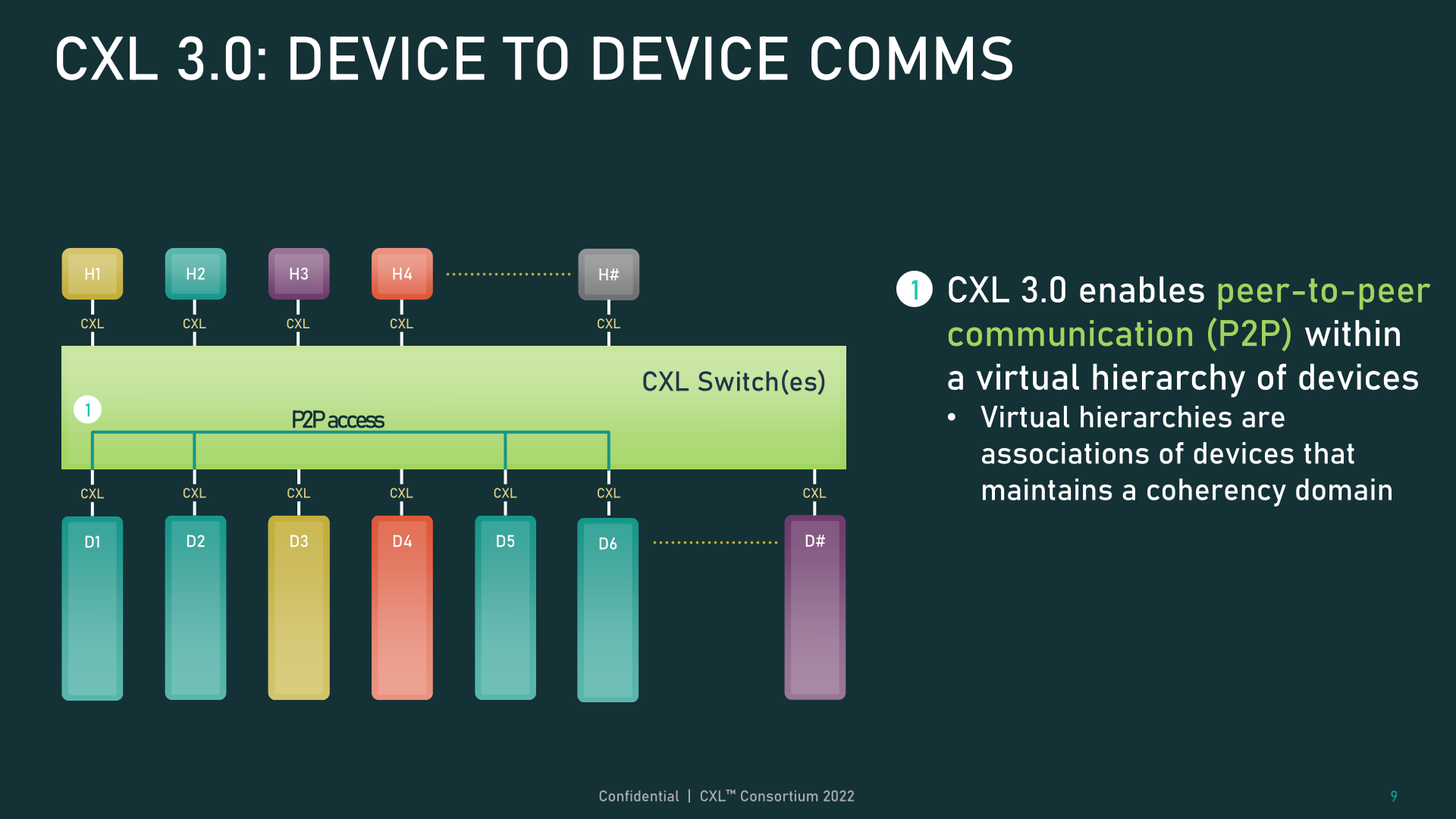
The inclusion of back invalidation also opens the door to new peer-to-peer connectivity between devices. In CXL 3.0, devices can now directly access each other’s memory without having to go through a host, using the enhanced coherency semantics to inform each other of their state. Skipping the host is not only faster from a latency perspective, but in a setup involving a switch, it means devices aren’t eating up precious host-to-switch bandwidth with their requests. And while we’ll get into topologies a bit later, these changes go hand-in hand with larger topologies, allowing devices to be organized into virtual hierarchies, where all of the devices in a hierarchy share a coherency domain.
Along with tweaking cache functionality, CXL 3.0 also introduces some important updates to memory sharing between hosts and devices. Whereas CXL 2.0 offered memory pooling, where multiple hosts could access a device’s memory but each had to be assigned their own dedicated memory segment, CXL 3.0 introduces true memory sharing. Leveraging the new enhanced coherency semantics, multiple hosts can have a coherent copy of a shared segment, with back invalidation used to keep all the hosts in sync should something change on the device level.
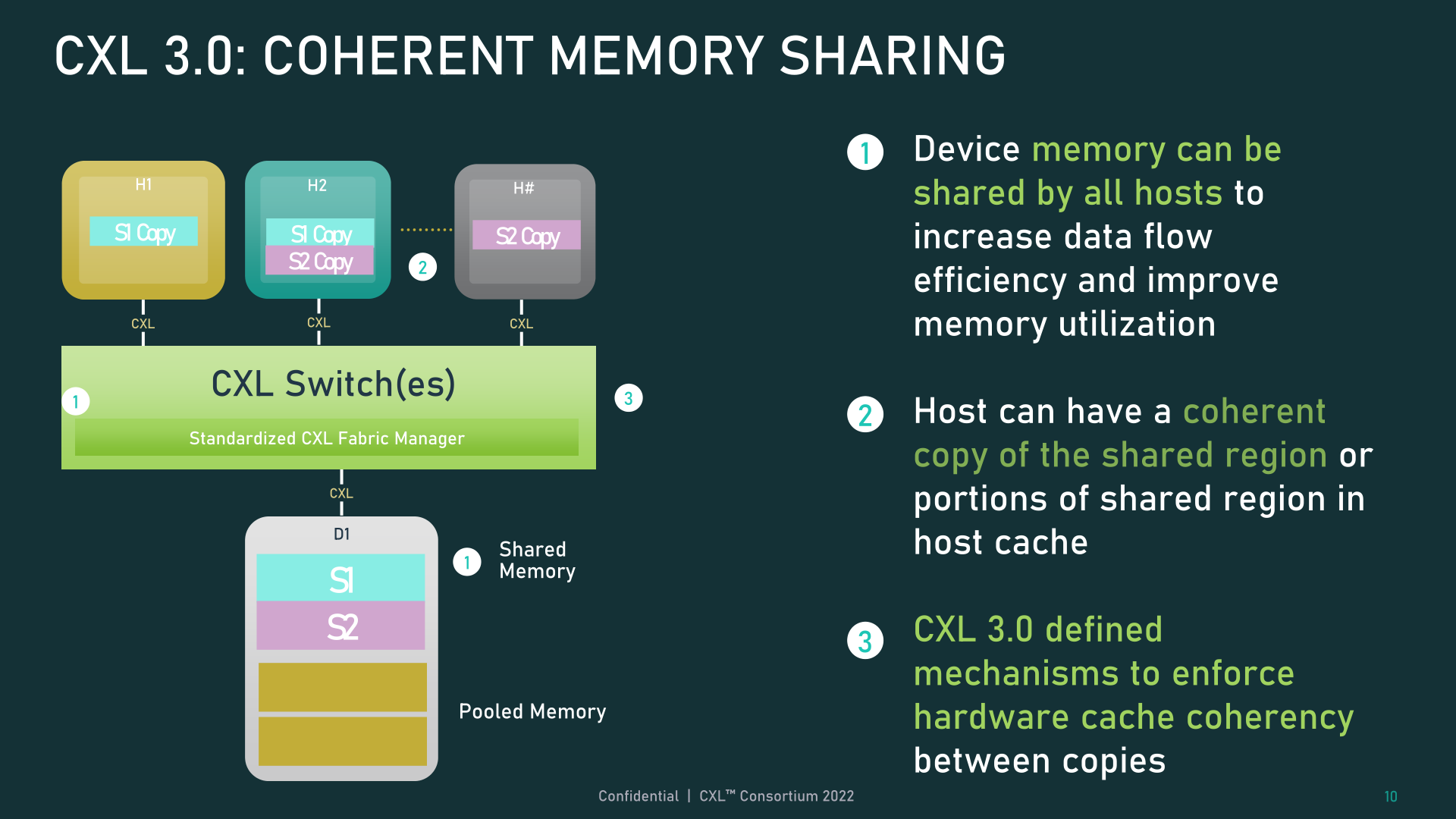
It should be noted, however, that this doesn’t entirely replace pooling. There are still use cases where CXL 2.0-style pooling would be preferable (maintaining coherency comes with trade-offs), and CXL 3.0 supports mixing and matching the two modes as necessary.
Further augmenting this improved host-device functionality, CXL 3.0 does away with the previous limitations on the number of Type-1/Type-2 devices that can be attached downstream of a single CXL root port. Whereas CXL 2.0 only allowed for a single one of these processing devices to be present downstream of a root port, CXL 3.0 lifts those limitations entirely. Now a CXL root port can support a full mix-and-match setup of Type-1/2/3 devices, depending on a system builder’s goals. Notably, this means being able to attach multiple accelerators to a single switch, improving density (more accelerators per host), and making the new peer-to-peer transfer features far more useful.

The other big feature change for CXL 3.0 is support for multi-level switching. This builds upon CXL 2.0, which introduced support for CXL protocol switches, but only allowed for a single switch to reside between a host and its devices. Multi-level switching, on the other hand, allows for multiple layers of switches – which is to say, switches feeding into other switches – which vastly increases the kinds and complexities of networking topologies supported.

Even with just two layers of switches, this is enough flexibility to enable non-tree topologies, such as rings, meshes, and other fabric setups. And the individual nodes can be hosts or devices, without any restrictions on types.
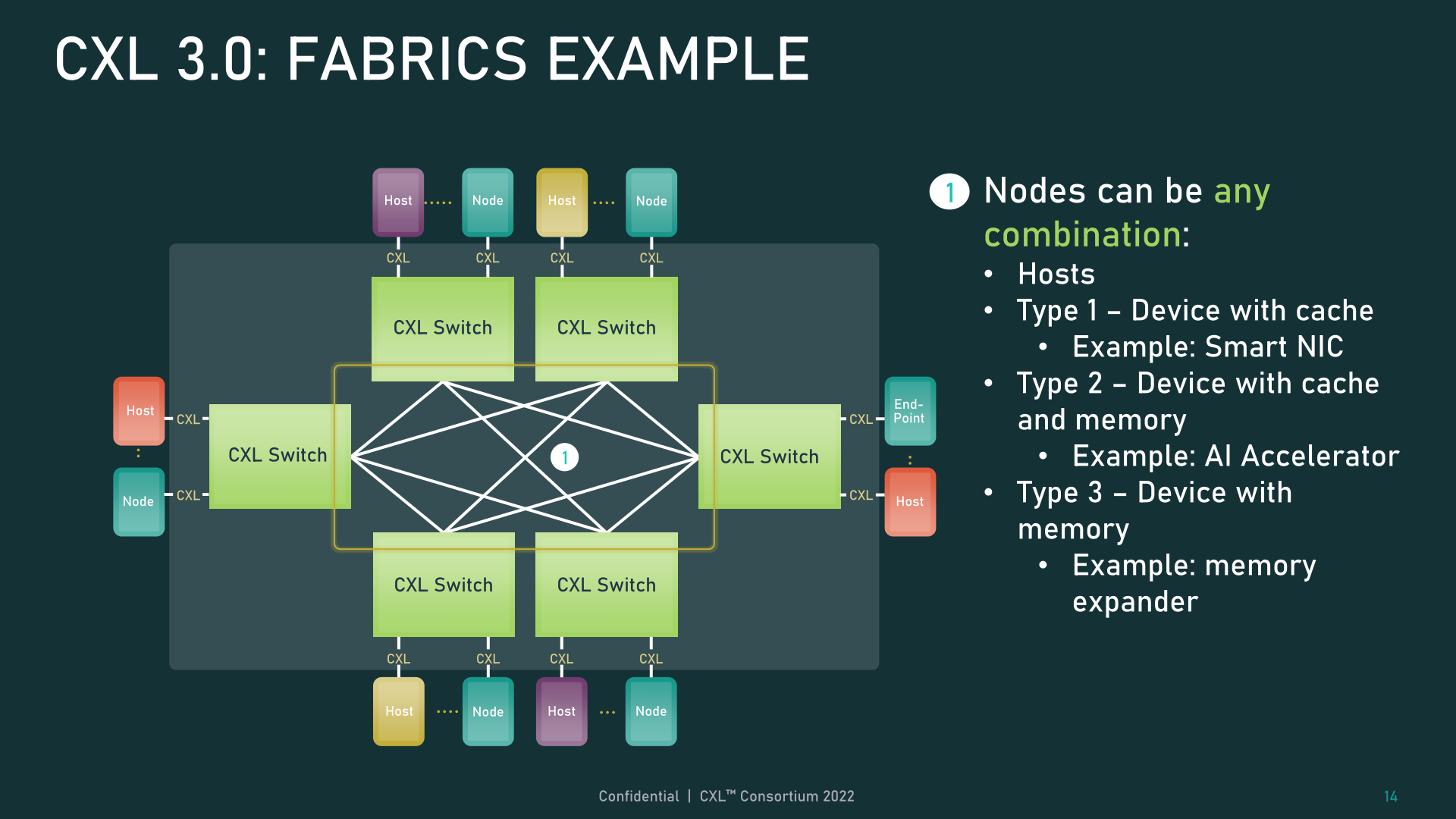
Meanwhile, for truly exotic setups, CXL 3.0 can even support spine/leaf architectures, where traffic is routed through top-level spine nodes whose only job is to further route traffic back to lower-level (leaf) nodes that in turn contain actual hosts/devices.
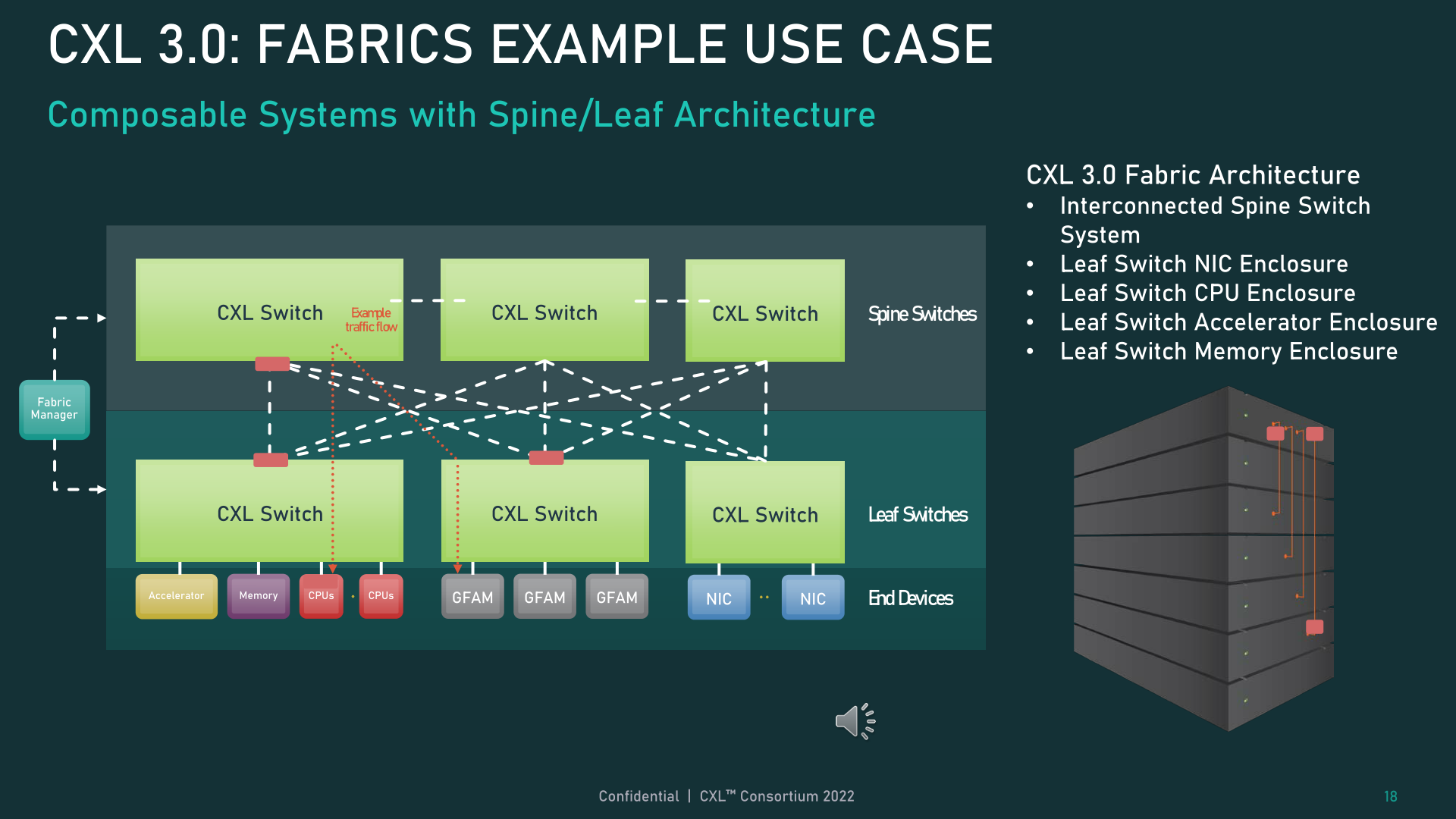
Finally, all of these new memory and topology/fabric capabilities can be used together in what the CXL Consortium is calling Global Fabric Attached Memory (GFAM). GFAM, in a nutshell, takes CXL’s memory expansion board (Type-3) idea to the next level by further disaggregating memory from a given host. A GFAM device, in that respect, is functionally its own shared pool of memory that hosts and devices can reach out to on an as-needed basis. And a GFAM device can contain both volatile and non-volatile memory together, such as DRAM and flash memory.
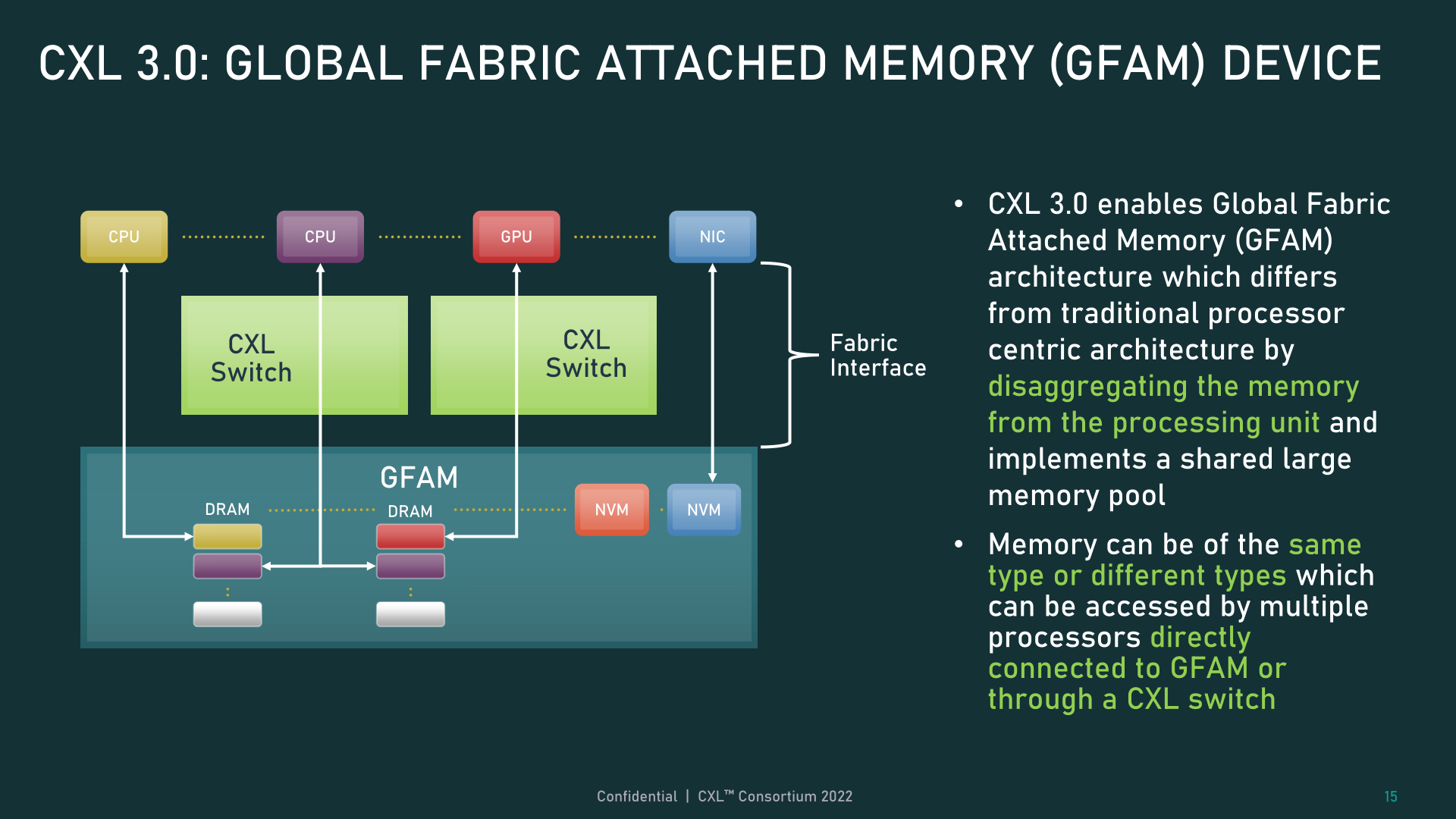
GFAM, in turn, is what will allow CXL to be used to efficiently support large, multi-node setups. As the Consortium uses in one of their examples, GFAM allows CXL 3.0 to offer the necessary performance and efficiency for implementing MapReduce over a cluster of CXL-connected machines. MapReduce, of course, is a very popular algorithm for use with accelerators, so expanding CXL to better handle a workload common to clustered accelerators is an obvious (and arguably necessary) next step for the standard. Though it does blur the lines a bit between where a local interconnect such as CXL ends, and a network interconnect such as InfiniBand begins.
Ultimately, the biggest differentiator may be the number of nodes supported. CXL’s addressing mechanism, which the Consortium calls Port Based Routing (PBR), supports up to 2^12 (4096) devices. So a CXL setup can only scale so far, especially as accelerators, attached memory, and other devices quickly eat up ports.
Wrapping things up, the completed CXL 3.0 standard is being released to the public today, the first day of FMS 2022. Officially, the Consortium doesn’t offer any guidance on when to expect CXL 3.0 show up in devices – that’s up to equipment manufacturers – but it’s reasonable to say it will not be right away. With CXL 1.1 hosts just now shipping – never mind CXL 2.0 hosts – the actual productization of CXL is lagging the standards by a couple of years, which is typical for these large industry interconnect standards.









3 Comments
View All Comments
JayNor - Saturday, August 6, 2022 - link
very nice coverage. I wonder if CXL 3.0 features will first be implemented over UCIE, with the system on chip roadmaps and 3d fab capabilities emerging.I see that hotchips is going to have a day of cxl 3.0 sessions this month.
JoeDuarte - Wednesday, August 24, 2022 - link
Anyone have numbers for latency? All I see are words like the same or reduced latency, for either CXL 3.0 or PCIe 6.0.I like OpenCAPI a whole lot because it has much lower latency than PCIe. Intel was very confused and incompetent in touting Optane's latency and bandwidth if they were just going to attach it to PCIe, wiping out its advantages. They needed a new interface for Optane to really add value, and that was OpenCAPI. I never heard of CXL having any latency advantages – it always seemed inferior, and for memory it adds latency, which is a waste. We need to reduce the latency of our computing systems at this point.
Priscillaarrison - Tuesday, October 4, 2022 - link
very nice coverage. I wonder if CXL 3.0 features will first be implemented over UCIE, with the system on chip roadmaps and 3d fab capabilities emerging.