Hot Chips 31 Live Blogs: Facebook Zion Unified Training Platform
by Dr. Ian Cutress on August 19, 2019 6:35 PM EST
06:34PM EDT - Facebook is presenting details on Zion, its next generation in-memory unified training platform.

06:35PM EDT - Zion designed for Facebook sparse workloads
06:35PM EDT - Many teams at Facebook
06:35PM EDT - expertise from networking to infrastructure to compute
06:36PM EDT - 12 month ML Training growth is 3x compute
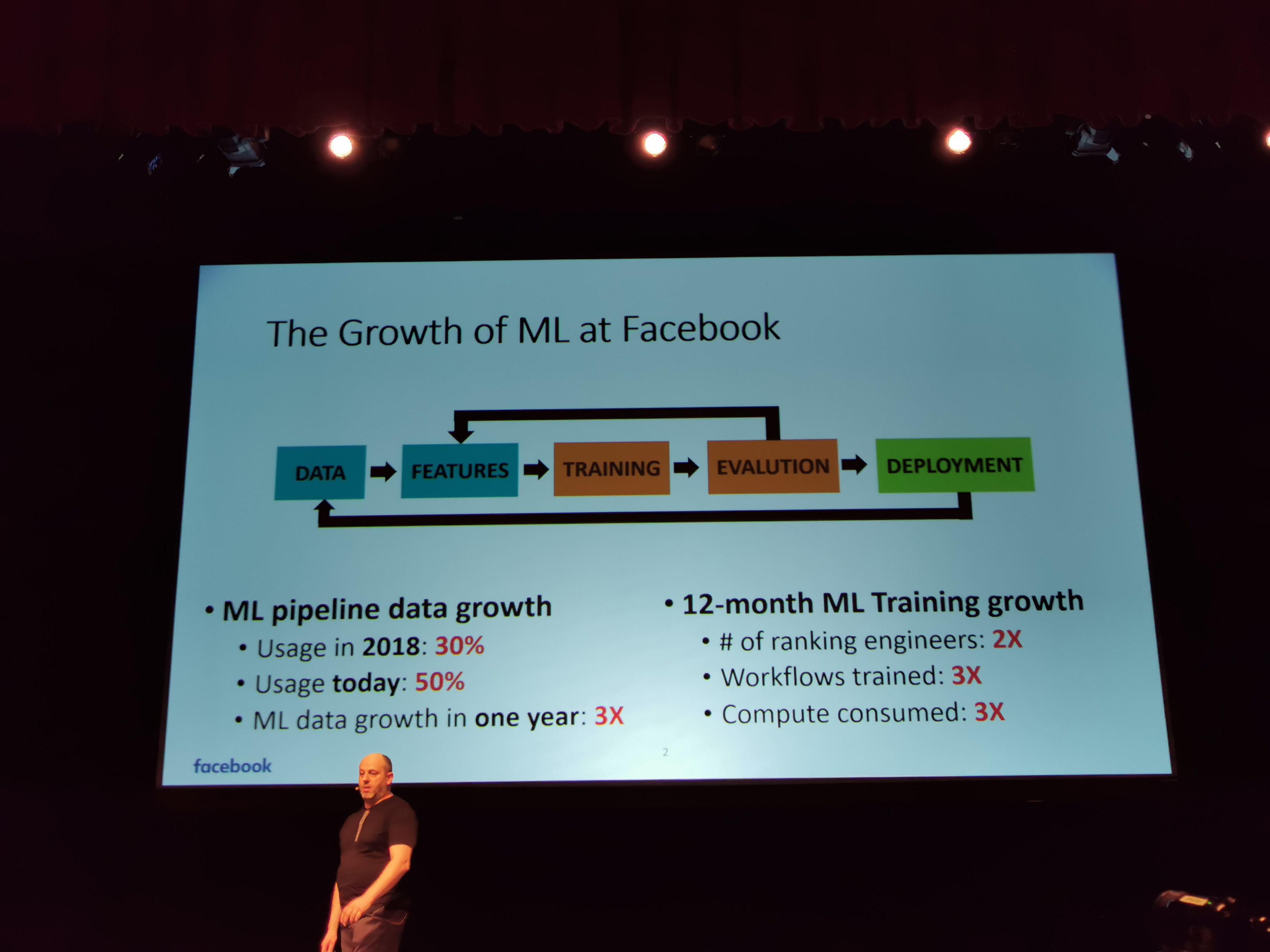
06:36PM EDT - ML pipeline data growth in 2018 was 30%, now is 50%
06:36PM EDT - That's 30% of the DC, now 50%
06:37PM EDT - The size of the datacenter has doubled in the same timeframe, so overall 3x
06:37PM EDT - Number of engineers on ML experimenting with models has 2x in the last 12-months
06:37PM EDT - These place significant strains on the systems
06:37PM EDT - ML engineers expect to do it in a very agile form

06:38PM EDT - They need flexibility and efficiency
06:38PM EDT - Motivated SW/HW co-design
06:38PM EDT - Strains on different parts of the datacenter
06:38PM EDT - Major AI services at Facebook
06:39PM EDT - Recommendations, vision, language
06:39PM EDT - Three main high-level services
06:40PM EDT - The recommendation models are among the most important models, for news feed and such

06:40PM EDT - DL Models

06:41PM EDT - Many features are sparse in the workloads
06:41PM EDT - e.g. friend and user pages
06:41PM EDT - Need numerical model for training
06:41PM EDT - translated into embedded table lookups
06:42PM EDT - Develop interaction between features to help compute potential user interactivity
06:42PM EDT - Not every user will interact with every feature
06:43PM EDT - The models are quite extensive in resource requirements
06:43PM EDT - Stretch every element of the infrastructure
06:43PM EDT - Embedded tables are order of 10+ GB per user
06:43PM EDT - Low algorithmic intensity
06:44PM EDT - Aim for model parallelism
06:44PM EDT - Have to get good load balancing across multiple devices

06:44PM EDT - MLP (multi-layer perceptron) requires model or data parallelism
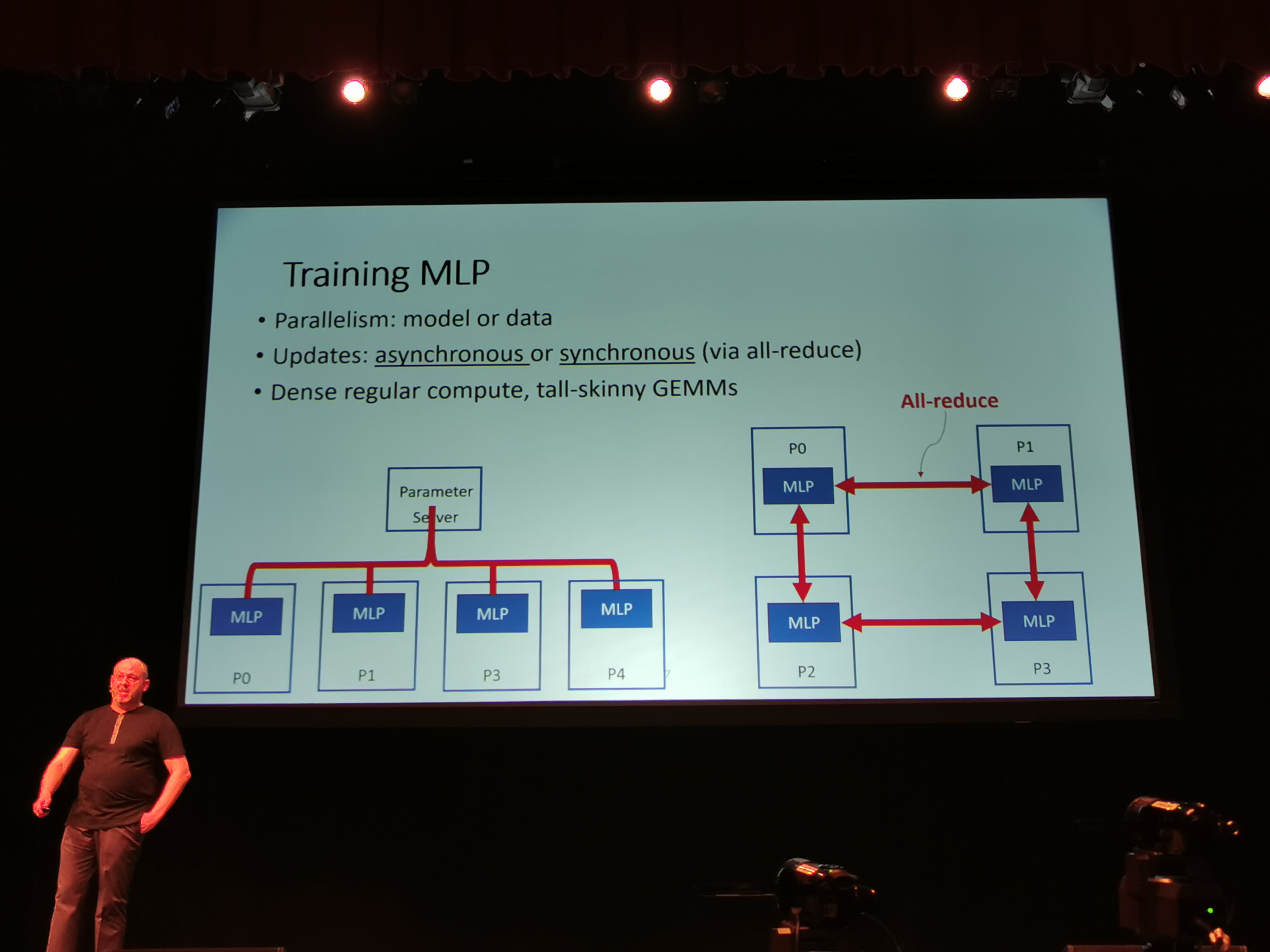
06:45PM EDT - Tall and skinny GEMM models
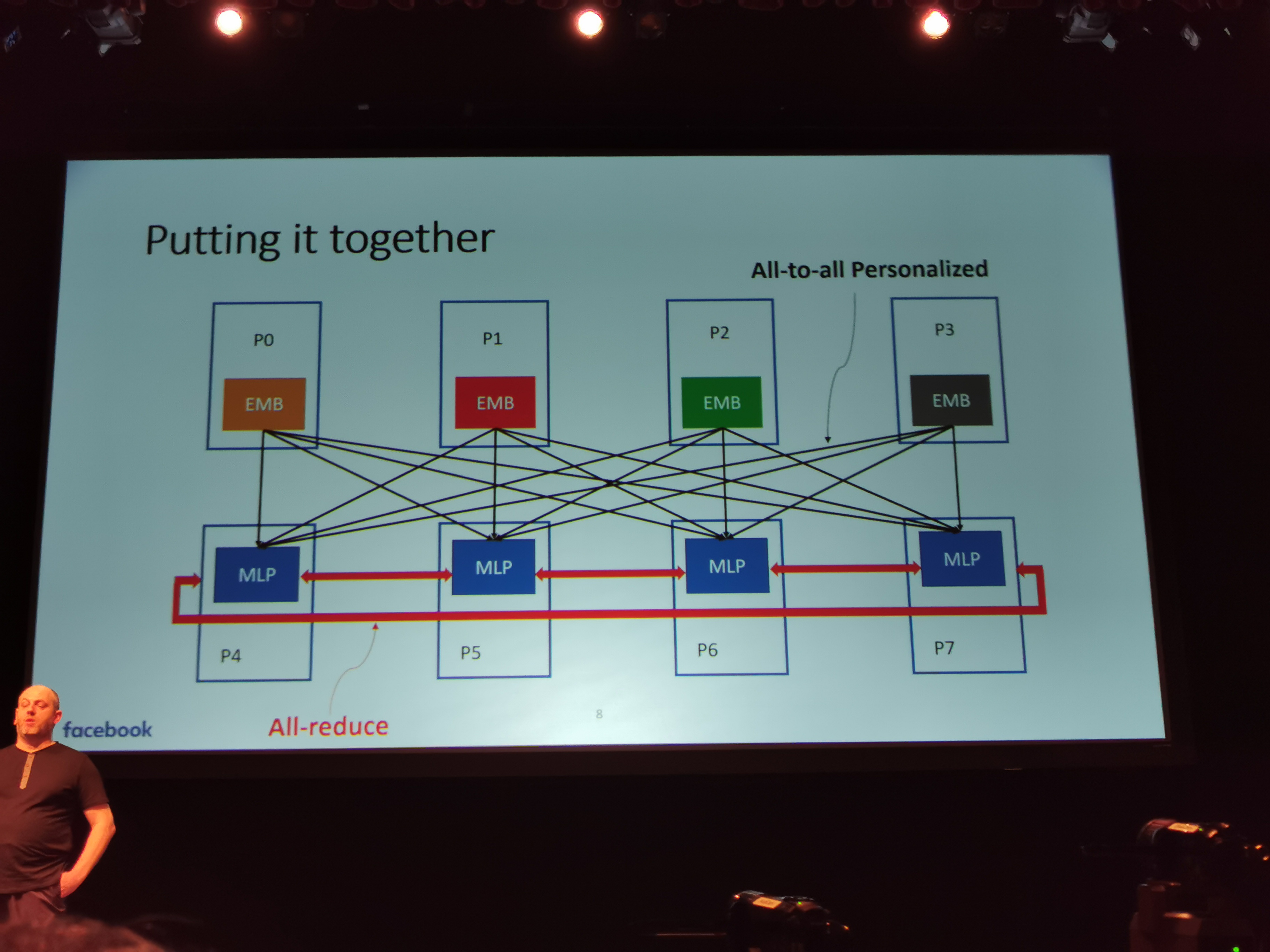
06:45PM EDT - Putting it all together
06:45PM EDT - Training each of the models
06:45PM EDT - All-to-all communications which strains the infrastructure
06:46PM EDT - Unified BF16 format with CPU and Accelerators
06:47PM EDT - 8 socket CPU system with 8 accelerators
06:47PM EDT - 8x100W CPU with 8x200W Accelerator
06:47PM EDT - Not all parts use BF16


06:48PM EDT - CPU organized in hypercube mesh with separate fabric to accelerator fabric
06:48PM EDT - Designed to scale out
06:49PM EDT - (CPU must have BF16 = Cooper Lake?)
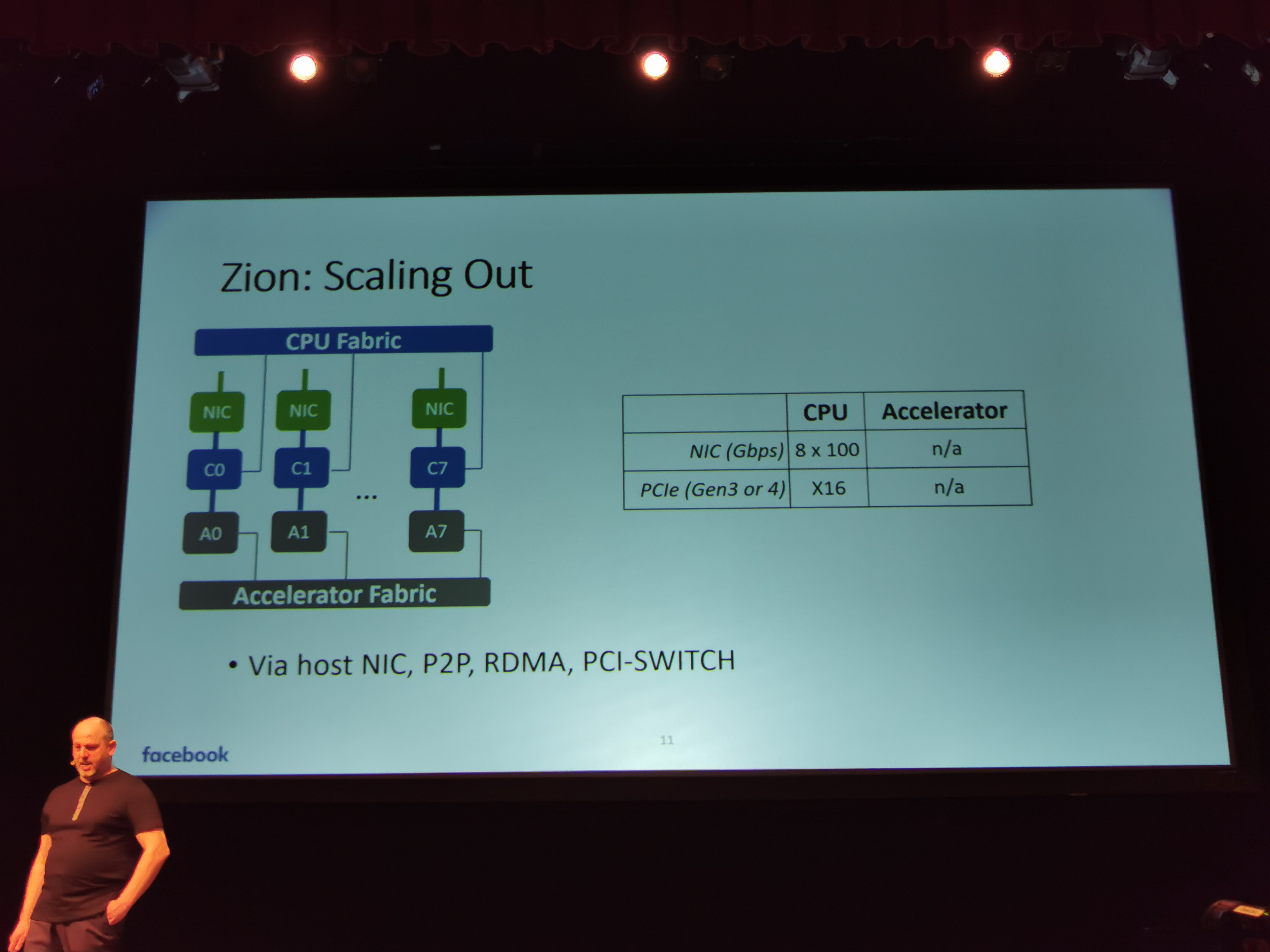
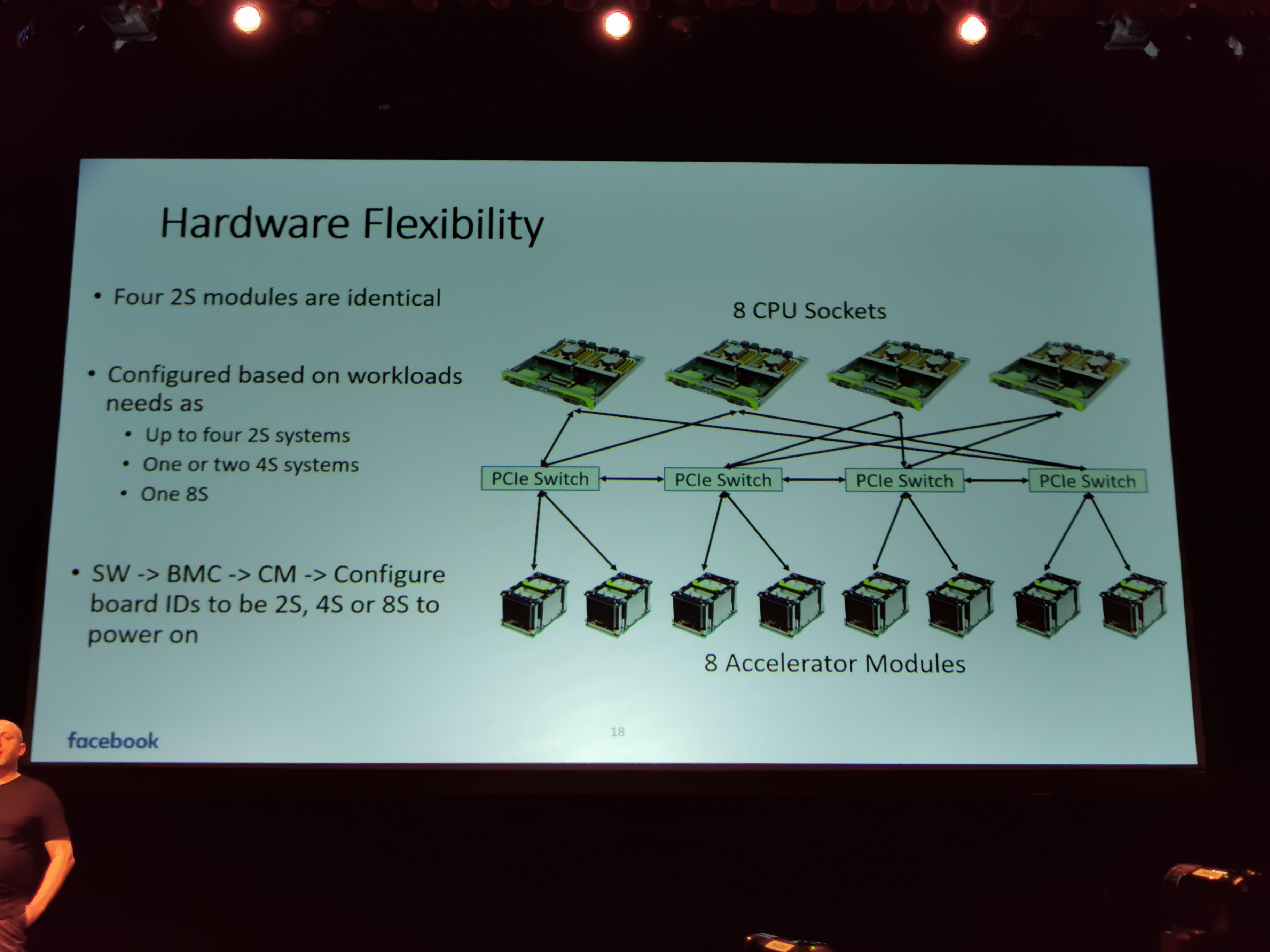
06:49PM EDT - Modular system design
06:49PM EDT - dual socket MB module
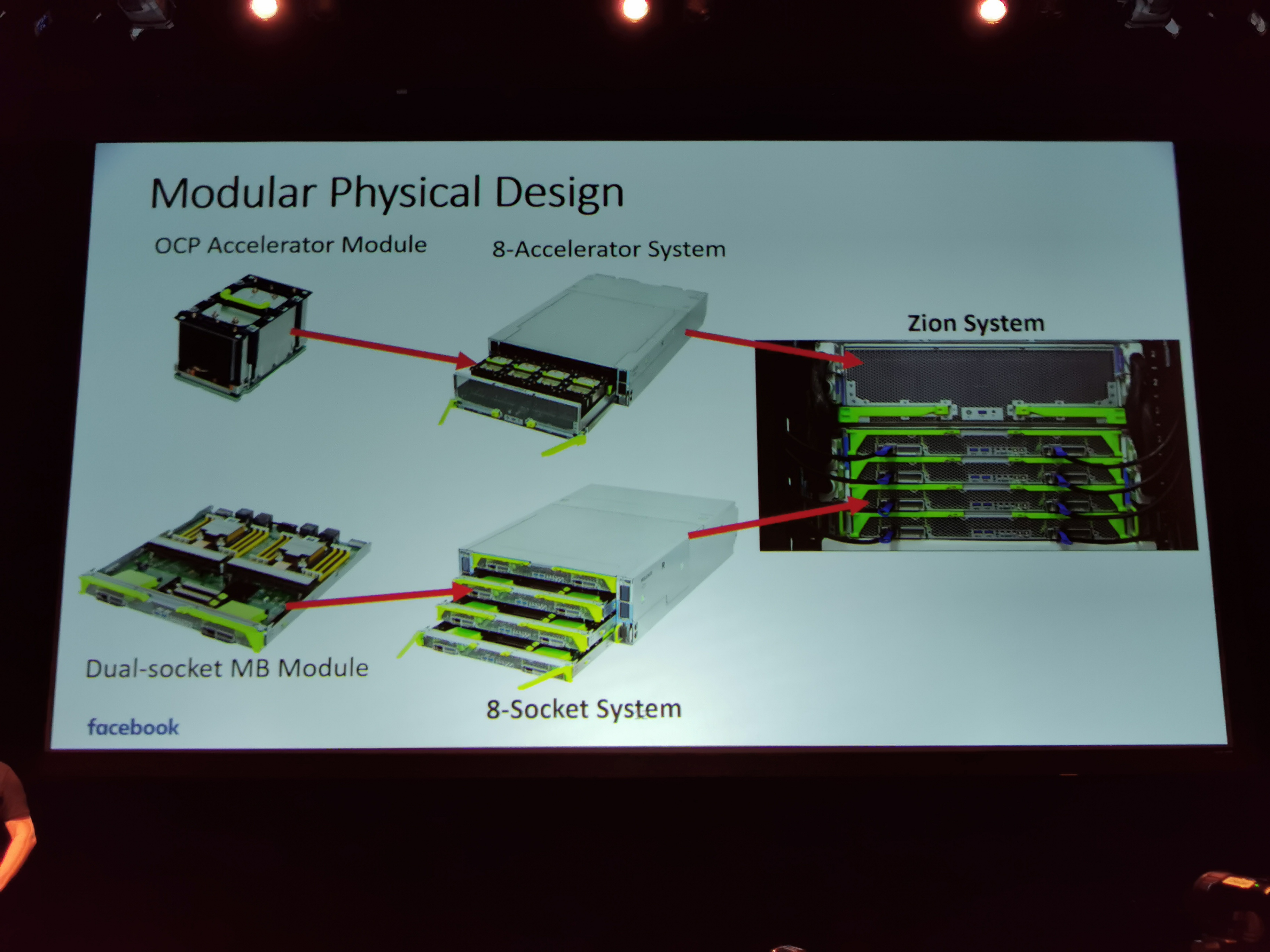
06:50PM EDT - four dual socket modules make an 8-socket system
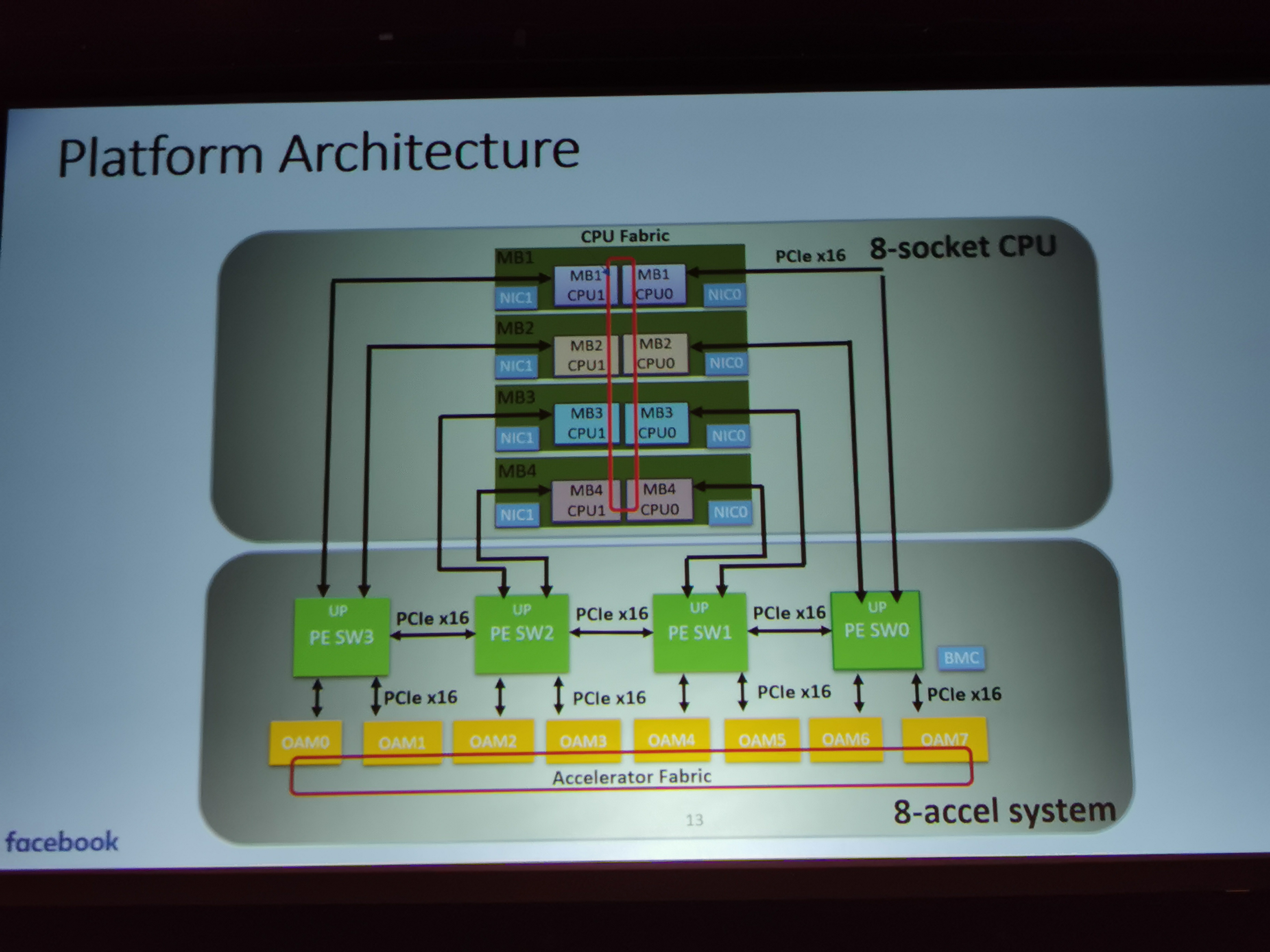

06:51PM EDT - Large number of different accelerators available. Facebook led OAM effort to device vendor agnostic common form factor
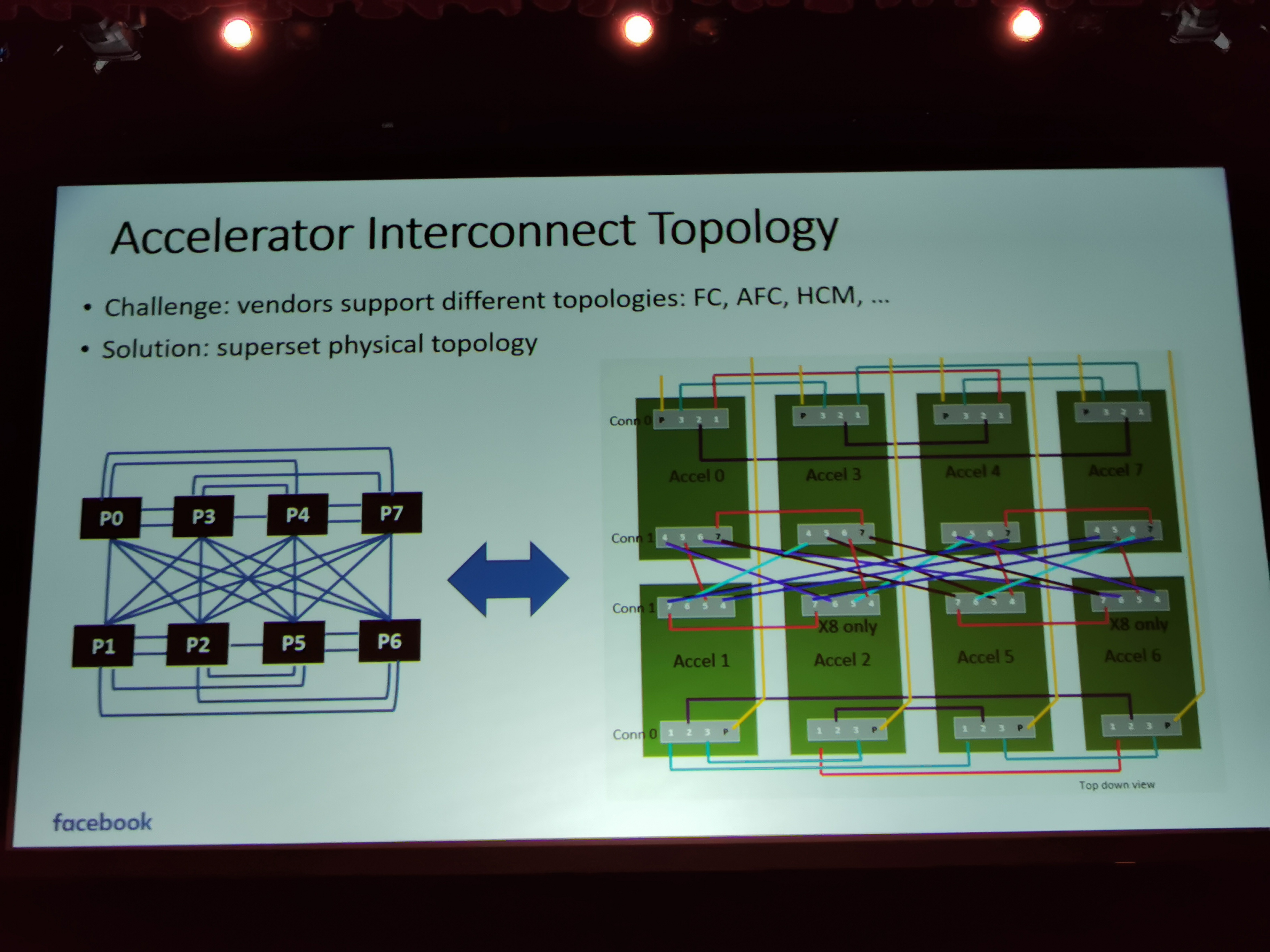
06:51PM EDT - Some vendors have cube mesh, some are fully connected
06:51PM EDT - Solution was the super set topology
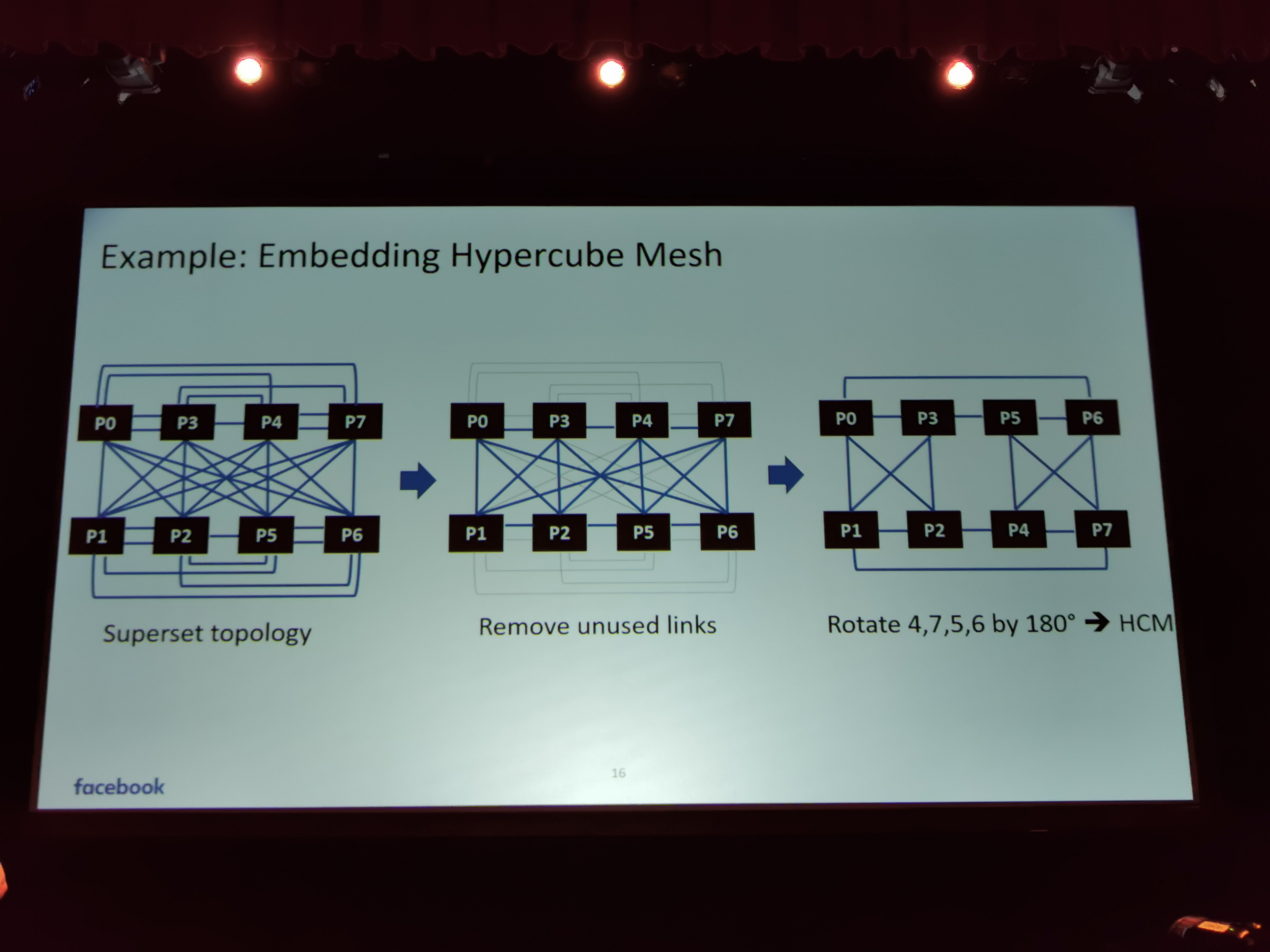
06:52PM EDT - Can enable all other topologies via superset

06:53PM EDT - Software flexibility
06:53PM EDT - Can work on CPU-only, and can increase the model on better hardware
06:53PM EDT - Creates a continuum of performance vs developer efficiency/time
06:54PM EDT - System can be configured as 4x2S, 2x4S, or 1x8S
06:54PM EDT - All works on PCIe
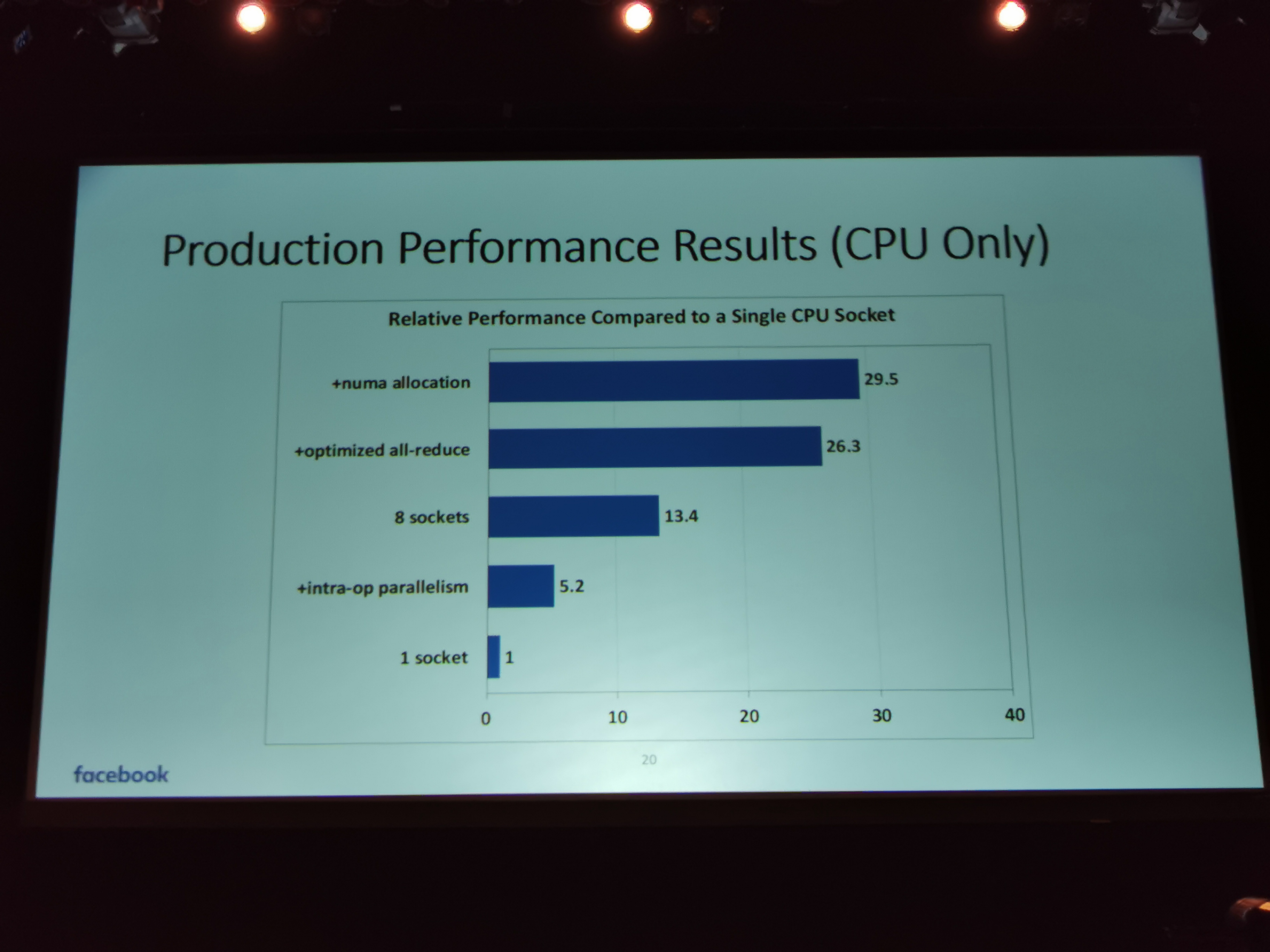
06:55PM EDT - Performance results, CPU only
06:56PM EDT - Comparison to NVIDIA solution


06:58PM EDT - That's a wrap








0 Comments
View All Comments