AMD Carrizo Part 2: A Generational Deep Dive into the Athlon X4 845 at $70
by Ian Cutress on July 14, 2016 9:00 AM ESTLinux Performance at 3 GHz
Built around several freely available benchmarks for Linux, Linux-Bench is a project spearheaded by Patrick at ServeTheHome to streamline about a dozen of these tests in a single neat package run via a set of three commands using an Ubuntu 11.04 LiveCD. These tests include fluid dynamics used by NASA, ray-tracing, OpenSSL, molecular modeling, and a scalable data structure server for web deployments. We run Linux-Bench and have chosen to report a select few of the tests that rely on CPU and DRAM speed.
All of our benchmark results can also be found in our benchmark engine, Bench.
C-Ray: link
C-Ray is a simple ray-tracing program that focuses almost exclusively on processor performance rather than DRAM access. The test in Linux-Bench renders a heavy complex scene offering a large scalable scenario.
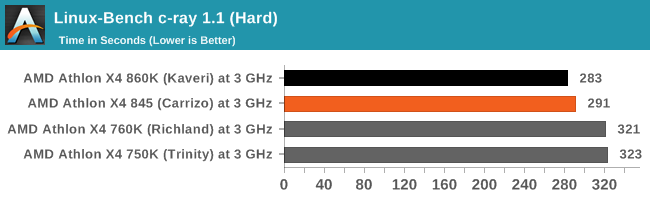
C-ray, while slowly fading in importance as a benchmark, shows a slight gain here for Kaveri despite the lack of DRAM accesses this benchmark uses. There may however still be some L2 use.
NAMD, Scalable Molecular Dynamics: link
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois at Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization up to and beyond 200,000 cores. The reference paper detailing NAMD has over 4000 citations, and our testing runs a small simulation where the calculation steps per unit time is the output vector.
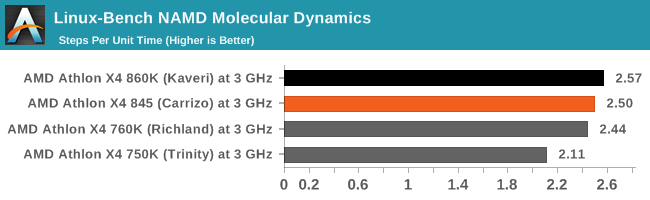
NAMD shows a small benefit for Kaveri here, with all three processors showing a +16% gain minimum over Trinity.
NPB, Fluid Dynamics: link
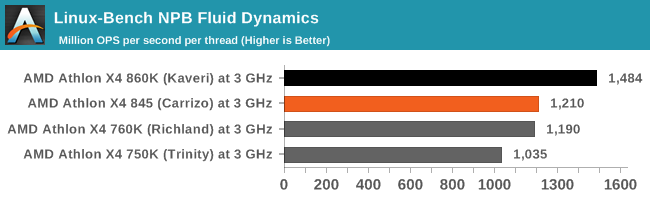
Aside from LINPACK, there are many other ways to benchmark supercomputers in terms of how effective they are for various types of mathematical processes. The NAS Parallel Benchmarks (NPB) are a set of small programs originally designed for NASA to test their supercomputers in terms of fluid dynamics simulations, useful for airflow reactions and design.
Redis: link
Many of the online applications rely on key-value caches and data structure servers to operate. Redis is an open-source, scalable web technology with a strong developer base, but also relies heavily on memory bandwidth as well as CPU performance.



The 2MB of L2 cache, compared to the 4MB of the other parts, hurts Carrizo here.








131 Comments
View All Comments
lefty2 - Thursday, July 14, 2016 - link
I'm predicting Bristol Ridge will be just as bad a failure as Carrizo. I.e. the few design wins will only have single DIMM memory and be universally unavailable, buried somewhere in a dark corner of the OEM's website. It's a pity, because both SoCs are very good in their own right.nandnandnand - Thursday, July 14, 2016 - link
If it's not Zen, it can be thrown straight in the garbage.Samus - Friday, July 15, 2016 - link
I still rock a few Kaveri desktops and they are incredibly powerful for the price. The 860K is half the cost of a comparable Intel chip, which supporting faster memory and a lower cost platform.Carizo on the desktop is an anomaly. I'd like to see what it could do with 4MB cache (would require an entirely new die)
Lolimaster - Saturday, July 16, 2016 - link
They were nice in 2014.We should have a nice 20nm 768SP APU in 2015 with a full L2 cache Excavator and fully mature 896SP 20nm early this year.
Remember the A8 3870K? That APU was a damn monster only hold back from being godly cause of their sub 3Ghz cpu speed, what we had after?
400SP VLIW5 2011 --> 384 VLIW4 2012 --> 384VLIW4 2013 --> 512SP GCN 2015 --> 512SP GCN 2016
Intel improved way faster (non "e" + edram igp's are near A8 level from being utter trash when the A8 3850 was release).
The_Countess - Tuesday, July 19, 2016 - link
yes being able to thrown in a extra billion transistors compared to AMD (1.7 vs 0.75 billion transistors for a quad core with GPU) because of 14nm really does help intel along a lot.but as nobody has been able to make a 20nm class process for anything but flash and ram besides intel, AMD's hands were tied. there is nothing AMD could have done to change that.
BlueBlazer - Friday, July 15, 2016 - link
Formula for failure: FM2 socket (with limited CPU upgradeability), only PCI Express x8 lanes available (which can bottleneck GPUs), and only "4 cores" (which performs more like 2C/4T Core i3 processor).neblogai - Friday, July 15, 2016 - link
Bristol Ridge is not FM2; PCI-E x8 can not bottleneck midrange GPUs; ultra low power mobile APU also sold as desktop chip is not a failure, just additional revenueBlueBlazer - Friday, July 15, 2016 - link
The results in the article shows otherwise, where AMD's Bristol Ridge was slower in most gaming tests, despite having better performance in some applications. Both FM2 and FM2+ are still the same (legacy) socket. AMD will be probably selling these chips at a loss. Note that these are the same (large) dies as Carrizo chips, and at 250mm^2 coupled with low prices typically meant razor thin margins or none at all.silverblue - Friday, July 15, 2016 - link
That L2 cache is probably making more difference than you realise.evolucion8 - Saturday, July 16, 2016 - link
The PCI-E is busted, even at PCI E 2.0 @ 4X, it barely makes a difference on the Fury X and the GTX 980 Ti.