Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
Sizing Things Up: Specifications Compared
Thirty-two high-IPC cores in one package sounds promising. But how does the best ThunderX2 compare to what AMD, Qualcomm and Intel have to offer? In the table below we compare the high level specifications of several top server SKUs.
| Comparison of Major Server SKUs | |||||
| AnandTech.com | Cavium ThunderX2 9980-2200 |
Qualcomm Centriq 2460 |
Intel Xeon 8176 |
Intel Xeon 6148 |
AMD EPYC 7601 |
| Process Technology | TSMC 16 nm |
Samsung 10 nm |
Intel 14 nm |
Intel 14 nm |
Global Foundries 14 nm |
| Cores | 32 Ring bus |
48 Ring bus |
28 Mesh |
20 Mesh |
4 dies x 8 cores MCM |
| Threads | 128 | 48 | 56 | 40 | 64 |
| Max. number of sockets | 2 | 1 | 8 | 4 | 2 |
| Base Frequency | 2.2 GHz | 2.2 GHz | 2.2 GHz | 2.4 GHz | 2.2 GHz |
| Turbo Frequency | 2.5 GHz | 2.6 GHz | 3.8 GHz | 3.7 GHz | 3.2 GHz |
| L3 Cache | 32 MB | 60 MB | 38.5 MB | 27.5 MB | 8x8 MB |
| DRAM | 8-Channel DDR4-2667 |
6-Channel DDR4-2667 |
6-Channel DDR4-2667 |
6-Channel DDR4-2667 |
8-Channel DDR4-2667 |
| PCIe 3.0 lanes | 56 | 32 | 48 | 48 | 128 |
| TDP | 180W | 120 W | 165W | 150W | 180W |
| Price | $1795 | $1995 | $8719 | $3072 | $4200 |
Astute readers will quickly remark that Intel's top of the line CPU is the Xeon Platinum 8180. However that SKU with its 205W TDP and $10k+ price tage is not comparable at all to any CPU in the list. We are already going out on a limb by including the 8176, which we feel belongs in this list of maximum core/thread count SKUs. In fact, as we will see further, Cavium positions the Cavium 9980 as "comparable" to the Xeon Platinum 8164, which is essentially the same part as the 8176 but with slightly lower clockspeeds.
However, it terms of performance per dollar, Cavium typically compares their flagship 9980 to the Intel Xeon Gold 6148, against which the pricing of Cavium's CPU is very aggressive. Many of Cavium's benchmarks claim that the fastest ThunderX2 is 30% to 40% ahead of the Xeon 6148, all the while Cavium's offering comes in at $1300 less. That aggressive pricing might explain the increasingly persistent rumors that Qualcomm is not going to enter the server market after all.
When looking at the table above, you can already see some important differences between the contenders. Intel seems to have the most advanced core topology and the highest turbo clockspeed. Meanwhile Qualcomm has the best chances when it comes to performance per watt, and has already published some benchmarking data that underlines this advantage.
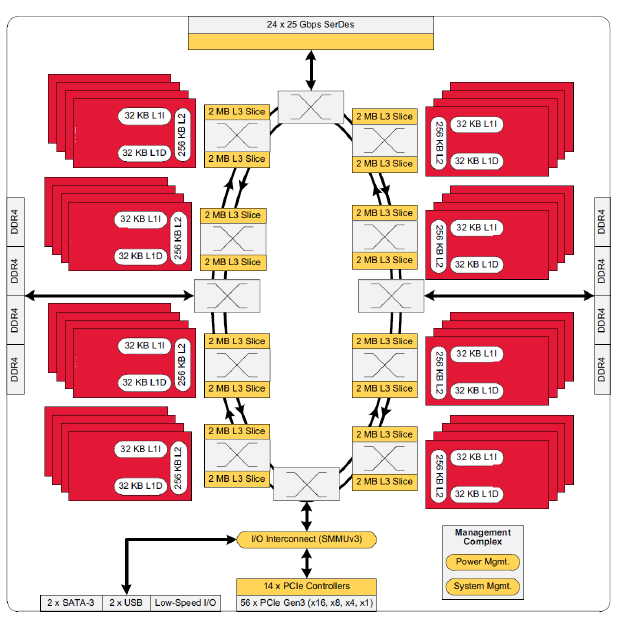
Similar to AMD's EPYC, Cavium's ThunderX2 is likely to shine in the "sparse matrix" HPC market. This is thanks to its 33% greater theoretical memory bandwidth and a high core/thread count. However as we've seen in the case of AMD's design, EPYC's L3-cache is slow once you need data that is not in the local 8 MB cache slice. The ThunderX2, by comparison, is a lot more sophisticated with a dual ring architecture, which seems to be similar to the ring architecture of the Xeon v4 (Broadwell-EP). According to Cavium, this ring structure is able to offer up to 6 TB/s of bandwidth and is non-blocking.
This ring architecture is connected to Cavium's Coherent Processor Interconnect (CCPI2 - at the top of the picture), which runs at 600 Gb/sec. This interconnect links the two sockets/NUMA nodes. Also connected to the ring are the SoC's 56 PCIe 3.0 lanes, which Cavium allocates among 14 PCIe "controllers.". These 14 controllers can, in turn, be bifurcated down to x4 or x1 as you can see below.

SR-IOV, which is important for I/O virtualization (Xen and KVM), is also supported.








97 Comments
View All Comments
name99 - Thursday, May 24, 2018 - link
For crying out loud!At the very least, if you want to pursue this obsession regarding vectors, look at ARM's SVE (Scalable Vector Extensions). THAT is where ARM is headed in the vector space.
Fujitsu is implementing these for the cores of its next HPC machines, and they will likely roll out into other ARM cores (maybe Apple first? but who can be sure?) over the next few years.
To the extent that Cavium has any interest in competing in HPC, if/when they choose to do so it will be on the basis of an SVE implementation, not on the basis of NEON.
Meanwhile ARMv8 NEON is very much the equivalent of SSE. Not AVX, no, but SSE (in all its versions) yes.
tuxRoller - Thursday, May 24, 2018 - link
Nice comment.BTW, centriq (rip) only supports(ed) aarch64. I've no idea how much die space that saved, though.
Wilco1 - Thursday, May 24, 2018 - link
There is Cortex-A35, smallest AArch64 core so far with FP and Neon.However there are still big differences between RISC and CISC. For example it's not feasible for CISC to get anywhere near the same size/perf/power. The mobile Atom debacle has clearly shown it's not feasible to match small and efficient RISCs even with a better process and many billions of dollars...
peevee - Thursday, May 24, 2018 - link
It is not 8.2.lmcd - Wednesday, January 23, 2019 - link
Necro but worth for historic reasons: A35 is AArch32 but ARMv8ZolaIII - Thursday, May 24, 2018 - link
It would took them a same. AVX is a SIMD FP extension to the prime architectural instruction set same as NEON and cetera. The strict difference between CISC and RISC architecture is long gone and today's one's are combined & further more implement IVIL SIMDs and more & more of DSP components as MAC's. The train only starts on prime integer instruction set (where by the way ARM is stellar) and then switches it's worker's to FP extensions and accelerated blocks of different kinds. The same way lintel grow up AVX to 512 bit in current use NEON can be scaled up & beyond. Fuitsu worked with ARM on 1024 & 2048 NEON SIMD blocks couple of years ago. Still if you think how FP is a best way to do it you are wrong, DSP's use CP and it's much more efficient power & performance wise but less scalable.On what would you like server's to be compared? Almost 90% of enterprise servers run on Linux, even Microsoft is earning more money this day's on Linux than from selling Windows desktop & server's combined.
You are very ignorant person. Why do you coment about the things you don't know anything about?
Ryan Smith - Thursday, May 24, 2018 - link
"I really think Anandtech needs to branch into different websites. Its very strange and unappealing to certain users to have business/consumer/random reviews/phone info all bunched together."Although I appreciate the feedback, I must admit that we enjoy doing a variety of things. There are a lot of cool things happening in the technology world, not all of which are in the consumer space. So rare articles like these - and we only publish a few a year - let us keep tabs on what's going on in some of those other markets.
HStewart - Wednesday, May 23, 2018 - link
I would think that a lot of this depends what type of applications are running on server. Highly mathematical and especially any with Vectors will be likely different. Also there is no support for Windows based servers which limits which applications can be done - so my guess this will be useless if desiring a VMWave server.But it is interesting that it takes a 4SMT to compete with x86 based servers from Intel and AMD and with more cores 32 vs 22/28 depending on version.
Wilco1 - Wednesday, May 23, 2018 - link
You're right, on floating point and vectors the results are different. To be precise - even more impressive. See the last page for example where it soundly beats Skylake on OpenFoam and a few other HPC benchmarks. Hence the huge interest from all the HPC companies.Note Windows has been running on Arm for quite some time. Microsoft runs Windows Server both on Centriq and ThunderX2. See eg. https://www.youtube.com/watch?v=uF1B5FfFLSA for more info.
HStewart - Wednesday, May 23, 2018 - link
Windows on ARM is DOA,